
Step 2: SSH into your new Zookeeper node In case you're new to Amazon like me, it's best to create some keys, provide them to EC2 and when you're provisioning your new node select your keys!
Well, here we are again Kafka my old friend..
I'm new to EC2 but my experience so far has been good. I wanted to throw this tutorial together not only for others, but for myself as a "remember how you did this guide". Step 1: Pick some random instance types I'm going to go ahead and pick 1 smaller node for Zookeeper and 2 nodes for Kafka. I used Ubuntu Server 14.04 LTS, I deployed the following types of nodes:
Tip: Ensure you have a security group enabled and selected when you create your servers, once they are initiated you cannot switch groups (I found this out the hard way), also add in the firewall rules so that your servers can talk with one another. Look at me, I have a zookeeper node!
You should start seeing a bunch of stuff on your screen, look for any warnings or errors.
Step 4 - Install some Java love
Step 5 - Fire up Zookeeper
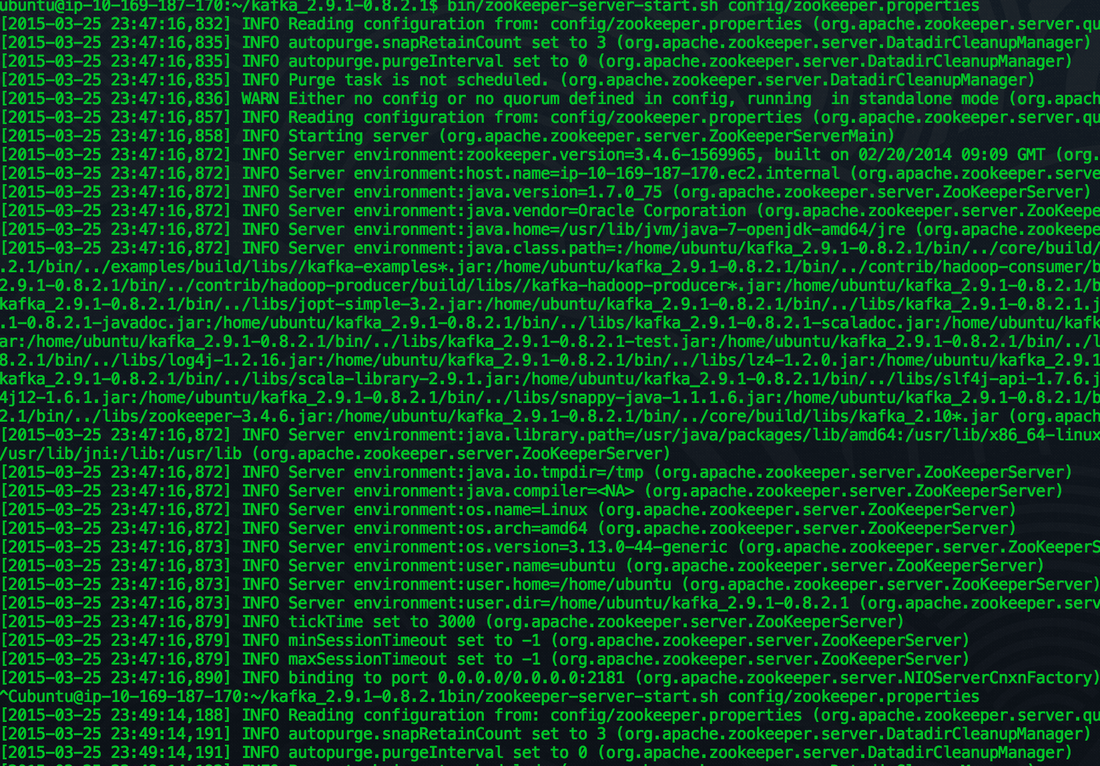
wget http://psg.mtu.edu/pub/apache/kafka/0.8.2.1/kafka_2.9.1-0.8.2.1.tgz
Step 3 - Download the latest package & unzip etc.
Remember to download the latest Kafka, you can check for versions here. We are going to be lazy and setup a single instance Zookeeper cluster. (remember to download the bin and not the src). cd kafka_2.9.1-0.8.2.1/ sudo apt-get install default-jre ssh -i ~/.ssh/your_ssh_key ubuntu@ec2-##-##-##-##.compute-1.amazonaws.com 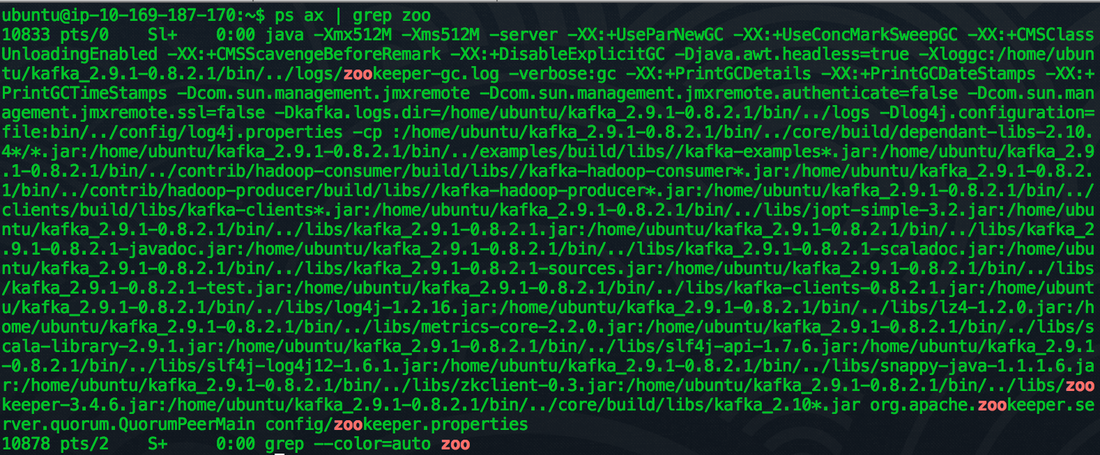
Step 6 - Fire up a couple of data nodes in EC2
Open up another terminal window and check that the zookeeper process is running: "ps aux | grep zoo"

Step 7 - Do the same on these nodes!
SSH into the data nodes and complete steps #3 and #4 again.
Step 8 - Change the configs for the data nodes
We need to update the data node configs to be able to talk with the Zookeeper node. In the terminal go to (use Vim or what ever text editor you like to fight over which is better).
Alter the following lines in both the data nodes:
nano config/server.properties broker.id=0
The broker.id is a unique integer, so if both of our data nodes are set to 0 we are going to have a bad time, change one of them to 1.
With zookeeper.connect you should change this from localhost to the ip address of the zookeeper node
Step 9 - Start up the data node servers!
bin/kafka-server-start.sh config/server.properties 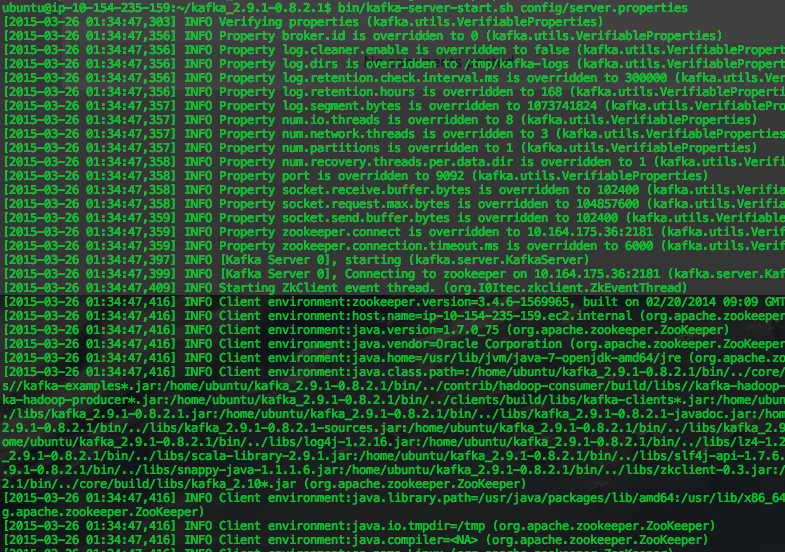
Same as the zookeeper node, you should start seeing messages spilling out to screen, ensure there aren't any warnings or errors in these logs.
Step 10 - Time to test this sucker!
Open up a new terminal window for each of your data nodes. We want to create your first topic, in the code below where it states "zooKeeperHostIP" replace that with the IP address of your zookeeper node. Run this command on either of your new terminal windows. bin/kafka-topics.sh --zookeeper zooKeeperHostIP:2181 --create --topic test --partitions 1 --replication-factor 1
Check to see if the topic has been created
bin/kafka-topics.sh --zookeeper zooKeeperHostIP:2181 --list
On one of the terminal windows, start up the consumer
bin/kafka-console-consumer.sh --zookeeper zooKeeperHostIP:2181 --topic test --from-beginning
On the other terminal window, add a producer:
bin/kafka-console-producer.sh --broker-list brokerOneIP:9092,broker2IP:9092 --topic test
Now.. on the terminal that you created the producer in, type "hello how are you!" Then watch the message appear on the consumer terminal window.
Producer: 
Consumer:

You might see a warning on the producer, "WARN Property topic is not valid" don't worry about that it seems like it's a bug.
Well done! We built our first multi-node Kafka cluster in Amazon EC2! I plan to expand on this in the coming weeks on monitoring and performance testing different instance types in Amazon.
7 Comments
Aaron
3/29/2015 12:38:05 am
This is a decent article. I've set up a few Kafka clusters in my time and aside from the ulimit issue I'd like to point out that using a single node Zookeeeper is going to set you up for failure. We run a 5 node Zookeeper ensemble and I suggest 5 as the minimum size. A 7 node would be much more stable. I'd also be interested in how you would approach a multi data center kafka cluster.
Ed Baker
3/29/2015 05:18:37 am
Hey Aaron, great catch! ... I think I mentioned in the article I was being a tad lazy on the zookeeper setup phase (but totally agree with you).
jatin
1/30/2016 02:56:28 pm
Can you please email or post high level changes you have made for
Nandan Rao
2/9/2016 07:35:02 am
This was very helpful, thank you!!
Syed Jameer
3/27/2016 11:47:10 pm
Hi,
Ed
3/28/2016 03:30:08 pm
We need more information on your data before a recommendation on partitions and replication can be made. The stock standard 3x replication is good if you're unsure, only go less than this is you're OK to lose data in case of failure and it's not business critical. Partitioning data should be worked out based on how your data is formed.
Aaron S
6/1/2018 06:19:42 am
Why are your steps all our of order? (2,1,4,5,3) Is this some sort of comment on distributed systems..? Leave a Reply. |

AuthorNew Zealand big data nerd, facial hair sculptor and classic car fanatic. Owner of needles.io, freelance big data consultant, ex Activision. Archives
April 2016
Categories
|
 RSS Feed
RSS Feed
