|
Hey you! Thinking about setting up Kafka? Gonna spend lots of money on super high spec machines? You know.. because processing millions of messages per second must need a billion cores, 124 wheel barrows of ram and a specialized SAN with 400 high speed SSD's. Well if you work in one of those horrible companies where your CTO's idea of product evaluation is forming partnerships with shitty vendors just to get a free cruise with 5,241 other wheel chair bound executives you might be screwed, BUT... if not then read on. NetFlix touts they are processing around 1.5 million events per second on peak.(I bet 90% of them are error logs.. jokes... well not really.. but I love Netflix). In my mind I was thinking.. that must require a fairly size-able cluster.. but like any engineer I wanted to see what kind and number of machines I would require to process "Netflix Scale" on Kafka. So, my test scenarios are below: Generic Across All Tests Zookeeper Node - r3.xlarge (30GB Memory, 4x vCPU, 1x80SSD) Producer - 3x m3.xlarge (7.5GB Memory, 2x vCPU, 2x32SSD) Zookeeper throughout the tests didn't flinch passed 10% on any benchmarks (but one node certainly isn't recommended in a production environment). Test 1 - General Purpose Nodes Brokers - 3x m3.xlarge (15GB Memory, 4x vCPU, 2x40SSD) Test 2 - Memory Optimized Nodes Brokers - 3x r3.4xlarge(122GB Memory, 16x vCPU, 1x320SSD) Test 3 - Well crap, I was stunned by the other two, I'm going to try something really bad. Brokers 3x m3.medium (3.75GB Memory, 1x vCPU, 1TB of magnetic EBS ..that's a max of IOPS of ~200!) Producers: We used the "org.apache.kafka.clients.tools.ProducerPerformance" class provided with Kafka to perform the tests. The producers each push 50,000,000 events with a payload of 100 BYTES each (thinking singular key-value events that you might push to something like Graphite), I also had async enabled and was batching events. Results: Test 1 (m3.xlarge) 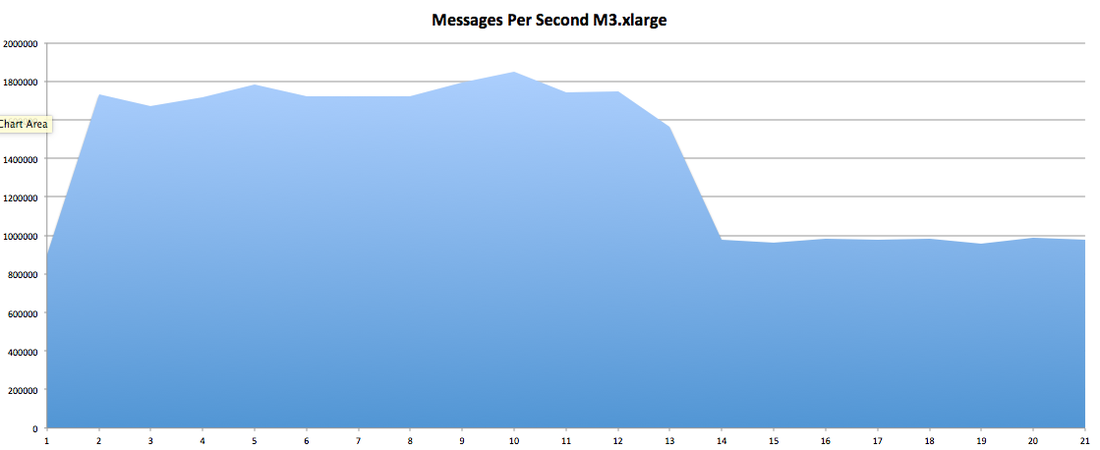 We hit a peak of 1.83 million records per second. You will see a sharp drop which is hard to explain as all of the producer nodes we used were exactly the same. One of the producers had the ability to process data 80% faster when it was the same spec as everything else is something I would put down to "cloud ghosts" if I had time I would have dug into more. Below you can see the graph by producer node: 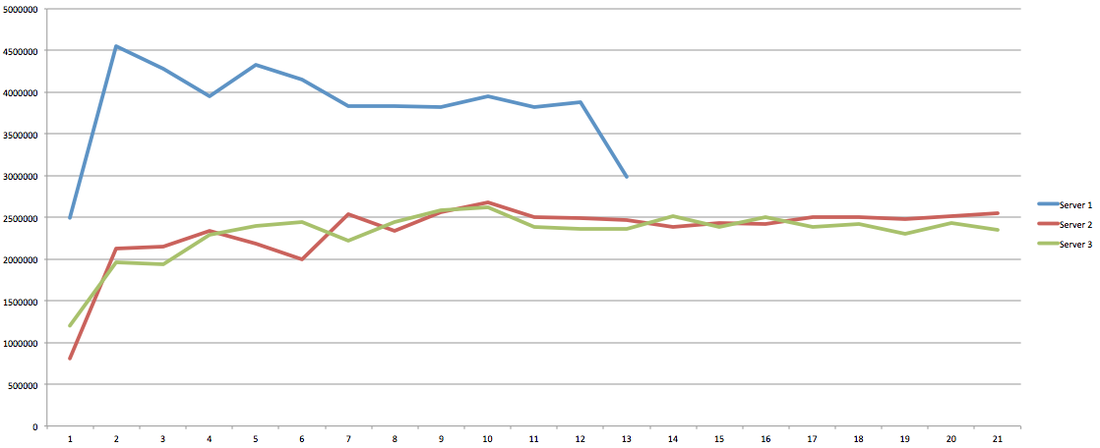 Details below pertaining to bytes in and out of the interfaces 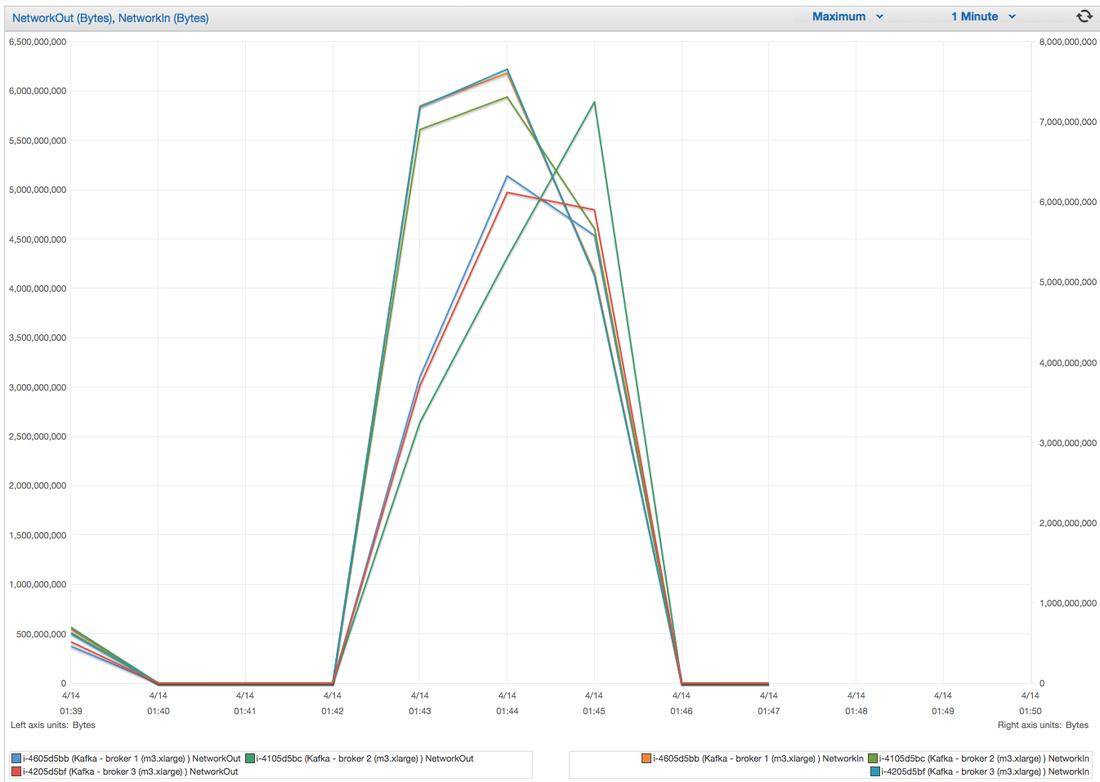 The last peak is ONLY relevant to the test (apologies!). We reached a peak just shy of 55% CPU utilization. 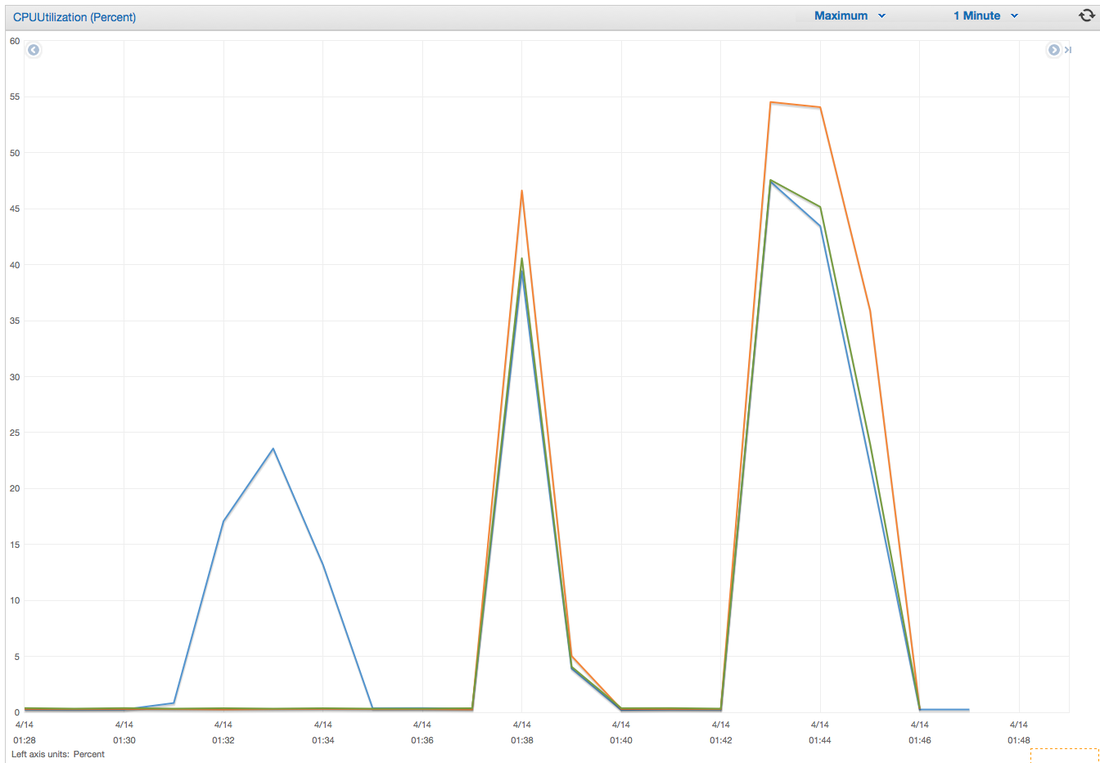 Results: Test 2 (R3.4 xlarge) 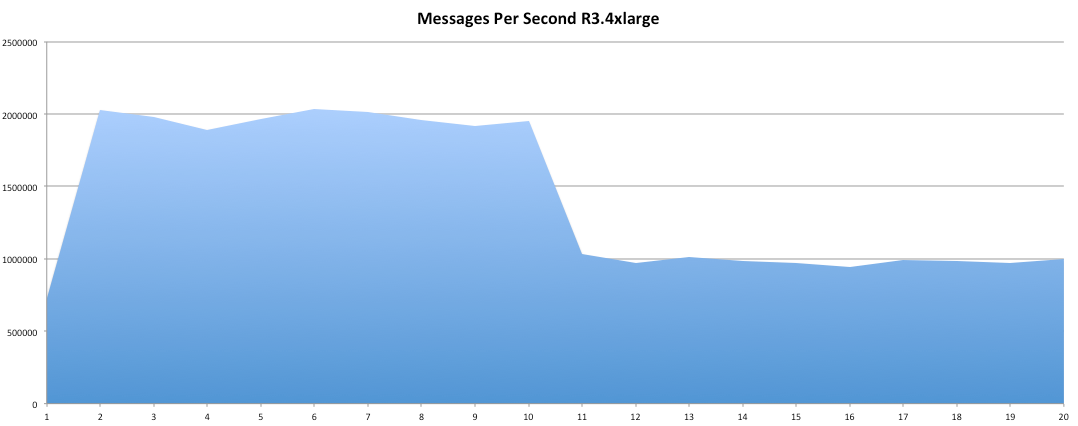 We peaked with just over 2 millions messages a second, again the same pattern shows that one producer is out performing the others quite a bit. 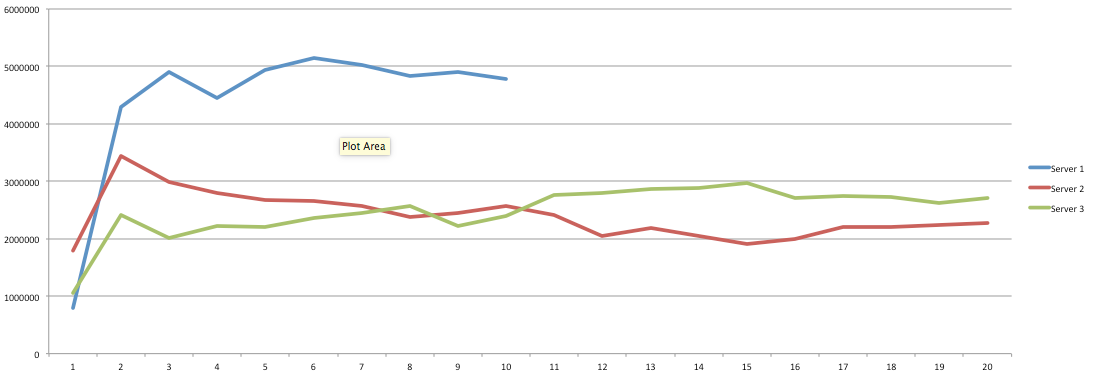 As the same in the last test, you can see producer server 1 leaping ahead and completing its messages much faster than the others. 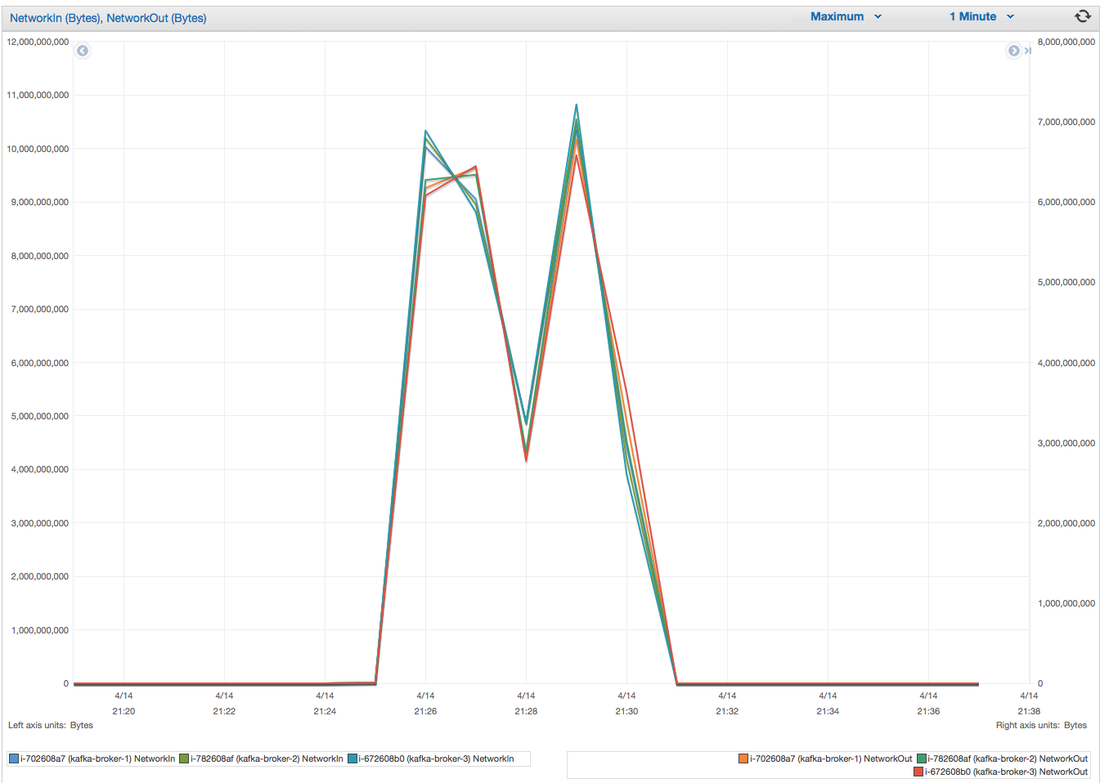 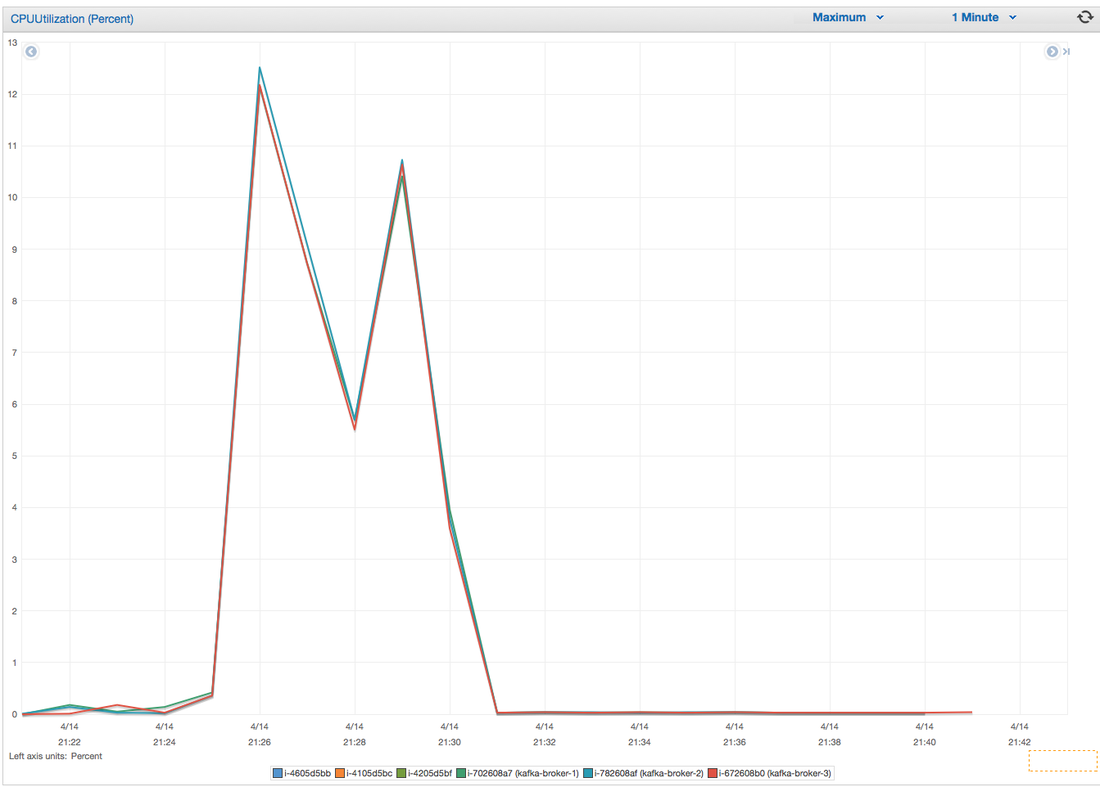 When you have 4x as many vCPU's, you have more lying around gathering dust. Results: Test 3 (m3.medium with EBS crappy disks) 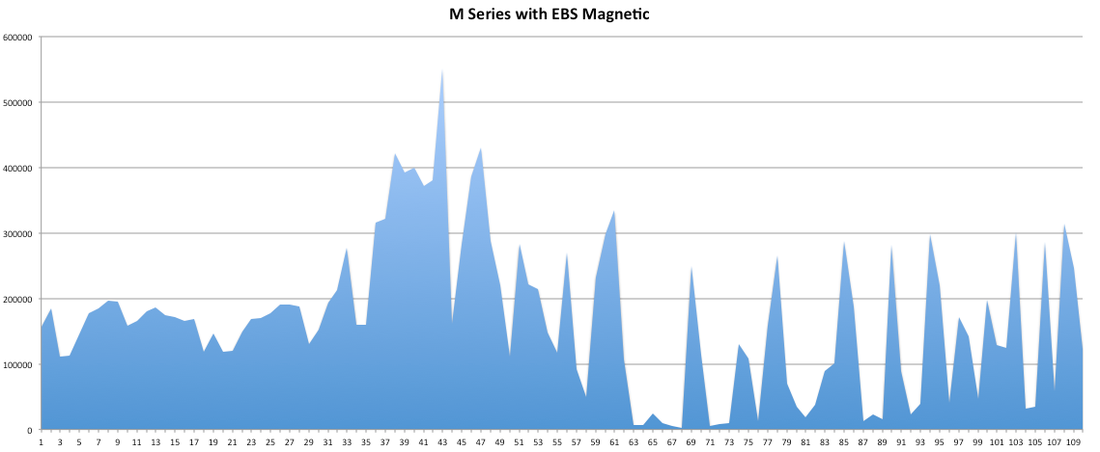 Woah there Nelly! Spiking up to ~550,000 messages per second and dropping to a low of ~2,400 per second, I guess when Amazon says "used for infrequent data access" you should maybe think twice about Kafka with magnetic EBS. 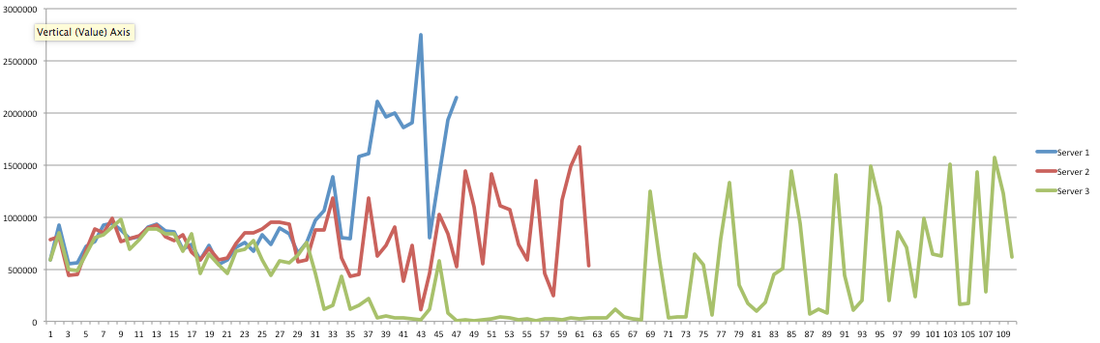 You can see the 3rd Producer node had a tough time of it, taking almost 2x longer to process 50mill events. 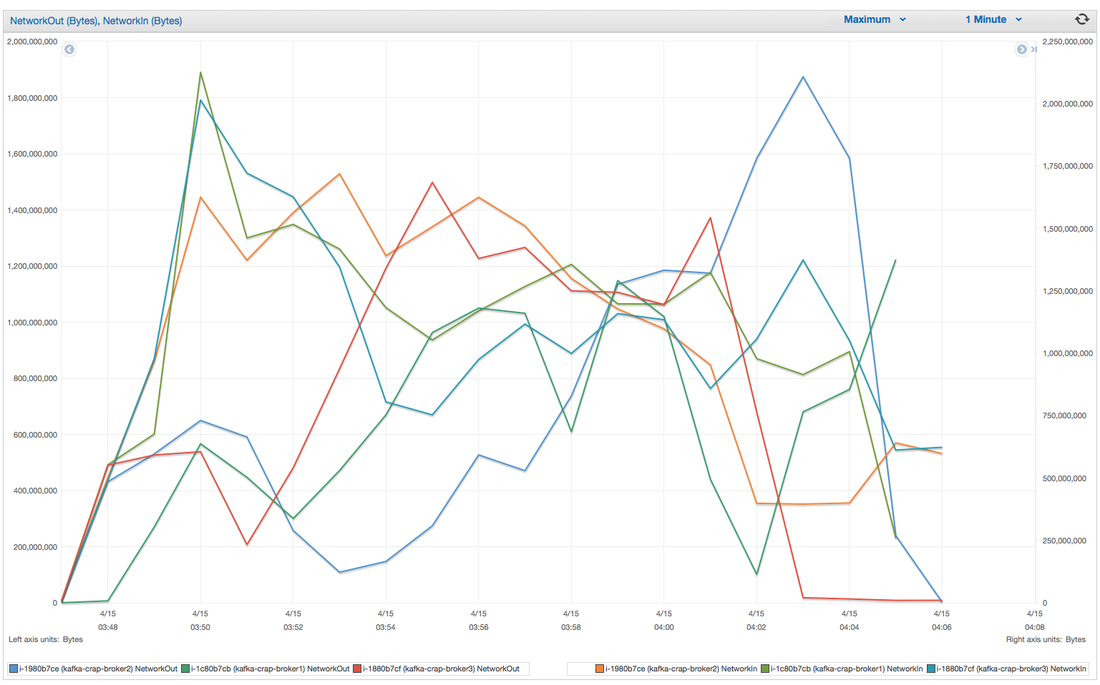 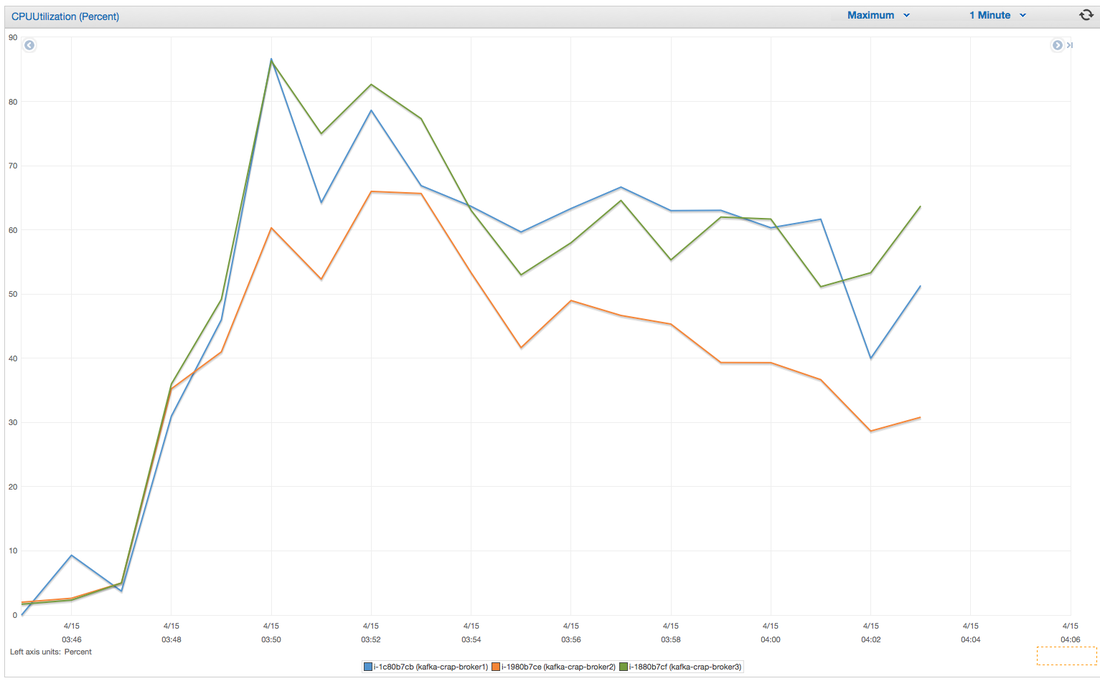 Network is all over the show, CPU is spiking up around 90%.
CONCLUSION Are you Netflix or Linkedin? Probably not.. but we did prove that we could process over 2 million messages a second? YES! and with the R based nodes we had room to grow! My aim was to prove that you can deploy something like Kafka, process shit tonnes of data along with it not breaking the bank! Although the R series had room to grow, I believe the m.series (not with EBS magnetic) is up to the challenge. I would have liked to have spent some time in the EBS SSD area with ranging payload sizes but these sets of tests have taken some time in their own right. The extra costs associated with your retention & replication policy coupled with firing around 1.5 million messages per second with our small payload of 100 bytes is around 150MB a second, when you do the math it gets pretty costly (if you have that many events I'm assuming your company is rather large and has deep pockets). We didn't fire up any consumers while the producers were running but I decided that since Jay saw very little difference between running with consumers and producers I left it out due to time. Update - Netflix are now saying 8,000,000 m/s during peak! Even with such an increase this is still very do-able on very basic kit in Ec2.
8 Comments
Anil
4/15/2015 07:07:31 pm
Nice work! What's your next experiment?
Anil
4/15/2015 08:11:41 pm
If you could publish something along these lines...
Jeff
6/25/2015 06:09:55 am
Hey Ed, just launched my own nodes through a friend and wanted to try some of these benchmarks out. Out of curiosity how did you produce those graphs? I don't suppose that's something that comes bundled with AWS?
Hey Mike,
Ed - thanks for the fast reply~
Lance Norskog
8/11/2015 09:26:06 am
Nice work! Leave a Reply. |

AuthorNew Zealand big data nerd, facial hair sculptor and classic car fanatic. Owner of needles.io, freelance big data consultant, ex Activision. Archives
April 2016
Categories
|
 RSS Feed
RSS Feed
