|
INTRO Lets cut to the chase, what's the difference between vertical and horizontal big data? Vertical A platform for hundreds of thousands of customers to run data analysis on their own service. Generally this service would be a feature to an existing product, for example:
Horizontal I put this is in the more traditional data warehouse category. A team collects data from a transactional event based system, munges it into a centralized store. A team of analysts / scientists job is to provide insights back to the business to help facilitate data design decisions into their core product (yes I know there are other use cases!). Not only are businesses using data to steer the ship, but people in their everyday lives want it also. Look at the adoption of stats around fitness for example, people depend on this information to help them make better decisions and help set goals. Companies are being forced to provide insights about all subject matter back to their customers, it's becoming an expectation around most new products. THE TRICKY BIT Now I could write an article all about Hadoop and how it has transformed an industry, but I have been working on hadoop for 6+ years and you can read about that practically anywhere. What I'm genuinely interested in is the challenges in Vertical Big Data services. Let me try and draw up a crappy google image for you to help illustrate the challenge: 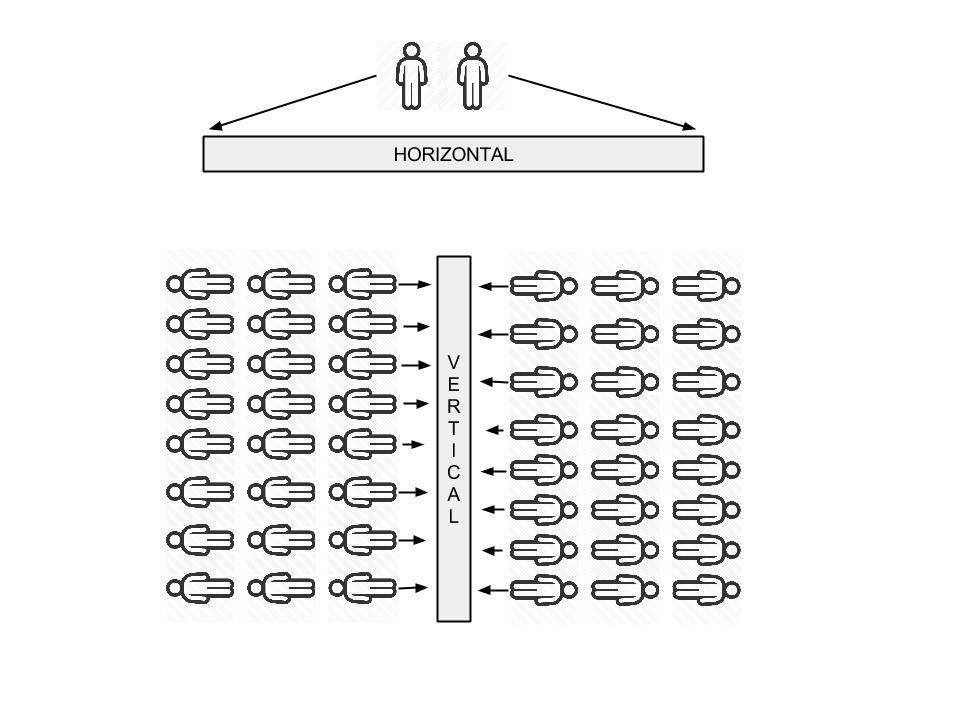 Horizontal (generalizations):
Vertical (generalizations):
HOW NOT TO DO VERTICAL You're using a product, lets say an auction site. You're a user looking for a new 2008 Honda Fit. Because you're tech savvy and like to save money, this auction site allows you to see average selling price of this particular model since it's inception in 2008 (time series). This allows you to see the models depreciation over time and will give you an idea on the selling price in 5 years when you buy a new Nissan GTR. The auctions site simply has a bit of sql like this that returns the result: SELECT avg(price), date FROM auctions WHERE make = 'honda' AND model = 'fit' AND year = '2008'; GROUP BY date; Now because the Auction house is "smart", Bill the DBA put some indexes in and it works just fine. When the product is released is all seems to go ok, after a few weeks the DB is slowly getting hammered as people are finding this new feature awesome and are using it to scan entire catalogs of makes and models to search for cars which will return the best return when they sell. What's worse is those lovely executives up on the top floor have found their magic sauce vs their competitors, "giving people reporting". They want more reports and fast, they don't care about stability as that's Bill's job, in Canadian.. they're saying "Git er done". Bill has three options:
Don't mix and match OLTP and OLAP to make some bastardized child "OLTPAP. Generally only use your transactional core product database for singular CRUD activities. If you're designing something that has any level of aggregation, that means your transactional data is working much harder. Modular separated services always win, if you design a new stack and it goes down due to load, it doesn't bring down the core product, customers are less angry, sure they don't know the history of Honda Fits, but they can still buy one. A high level of the wrong stack could look like this: 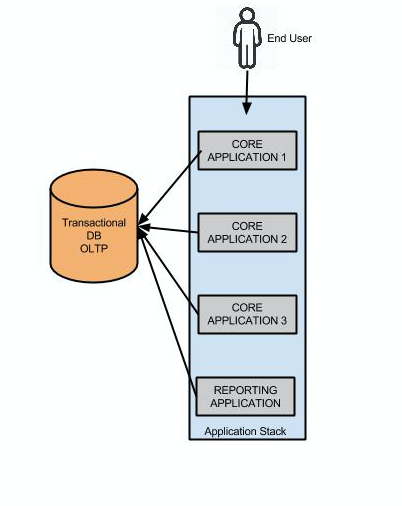 Separating out the customer reporting could look like this: 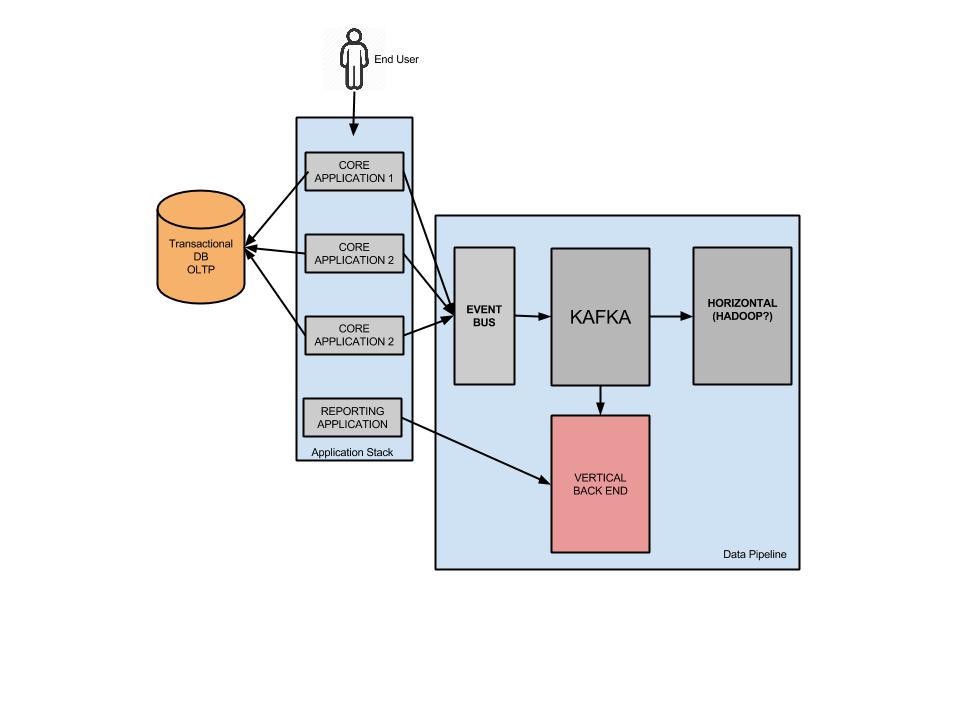 As illustrated above, we could utilize technologies like Kafka and Event buses (API ingestion) etc which can work in near to real time. The big questions is, what can go into that pink box to serve 100's of aggregated queries per second? There are a few options which I will run through. THE OLD TRIED AND TESTED You have been working with MYSQL for 10 years, you probably wrote your own sharding application, you flip master / slave roles and servers in your sleep. The developers can use their existing ORM to develop out of. The only issue is you're basically replicating your transactional db and it's not very cost efficient when you do the math. I won't go further into this one. DRUID.IO This lil guy popped into the scene a few years ago and is used quite widely internally at companies like NetFlix and EBay. In their words Druid is: Query timeseries data as it is being ingested for both immediate and historical insights. Aggregate, drill-down, and slice-n-dice N-dimensional data with consistent, fast response times. The way it works illustrated: 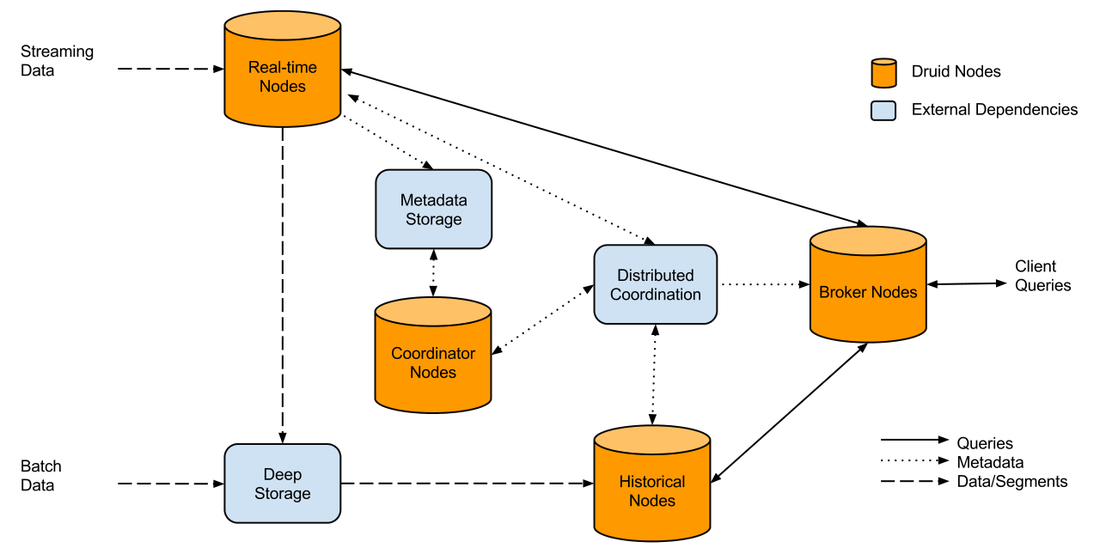 It can look a little daunting, and there is a lot moving parts (not as simple as a master/slave topology), but it is powerful in it's own right.
How does it work: It kind of cheats behind the scenes, once you send through an event it will roll it up based on the schema you provide the event , so three raw events might look like: customer_id, store_id, total_purchase, date 123 , 1 , $12, 2015/01/01 123 , 1 , $15, 2015/01/01 123 , 2 , $5, 2015/01/01 It would roll up it as so customer_id, store_id, total_purchase, date 123 , 1 ,$27 2015/01/01 123 , 2 ,$5 2015/01/01 Your dimensions in the druid schema would be: store_id and customer_id, metric would be total_purchase, granularity_spec set on "day" If your dimensions don't change very often, it has the possibility to be really good at rolling up to a handful of segments types. Pros
One thing I'm unsure of (didn't want to put it as a pro or a con) was could Druid handle 100's of queries a second? There might need to be a cache in front of druid which periodically pulls in fresh data, adding more complexity. NOSQL Take your pick! I'm going to be platform agnostic on this one (eg: cassandra, riak, mongo). But actually storing data inside an object per customer could be pliable especially if you have a low number of events per dimension(s). Storing the data but getting your application stack to do the aggregation at this level could be worth it. Now, this only works if the aggregations you want to provide are silo'd to a particular customer. If we use the example of the Auctions over time (as above), NOSQL could provide a little bit of a mess (aggregation over thousands of objects). But again there are several work around to this, you could run the aggregation in Hadoop which populates new service wide data views). SPARK STREAMING or STORM (my preferred option). Storm is the more mature platform, but Spark is being adopted at an alarming rate! Both require you to have your aggregations in memory (don't believe the lies). To facilitate less memory usage, writing out completed aggregation segments to a NOSQL solution like Cassandra can save you in the long run in terms of memory costs. Spark and Storm can run on Hadoop, so Hadoop can leverage the data as well for Horizontal type analysis. CONCLUSION Don't use your OLTP for aggregations, not even once. Do a bit of a brain storm on what types of reporting you plan to deliver to your customers now and in 2 years time, this kind of planning will save you all kinds of technical debt in the future. Is your reporting silo'd to one customers data (eg: financial)? Or are you going to share events from your entire customer base into the reports (eg: auction house). This will dictate the direction you need to go with in terms of picking the right tools.
13 Comments
12/17/2015 10:39:33 pm
Thanks for sharing informative post. I have read your blog. Its really useful for me to know more about big data hadoop. keep update your blog. 11/3/2016 02:34:33 am
Very informative piece of article, this blog has helped me to understand the concept even better. Keep on blogging. 5/16/2017 12:22:14 am
Thanks for posting useful information.You have provided an nice article, Thank you very much for this one. And i hope this will be useful for many people.. and i am waiting for your next post keep on updating these kinds of knowledgeable things...Really it was an awesome article...very interesting to read..please sharing like this information......
6/2/2017 02:39:24 am
It's hard enough to understand what the term "web development" means, without having to then get a grasp on all the jargon that is commonly used in the web development industry.
Thank you for the information, i found the information very useful.
Hi, 1/9/2022 11:26:38 pm
Very Informative blog thank you for sharing. Keep sharing.
Thank you for providing valuable information. Looking for Mobile repairing in Madurai? Look no further! Our <a href="https://careerpluz.in/iphone-repair-technician-course" >iPhone Technician Course</a><br>is tailored for enthusiasts seeking hands-on skills. Join us to unlock a world of knowledge and practical expertise.
Thank you for providing valuable information. Looking for Mobile repairing in Madurai? Look no further! Our <a href="https://careerpluz.in/iphone-repair-technician-course" >iPhone Technician Course</a><br>is tailored for enthusiasts seeking hands-on skills. Join us to unlock a world of knowledge and practical expertise.
Thank you for providing valuable information. Looking for Mobile repairing in Madurai? Look no further! Our <a href="https://careerpluz.in/iphone-repair-technician-course" >iPhone Technician Course</a><br>is tailored for enthusiasts seeking hands-on skills. Join us to unlock a world of knowledge and practical expertise. Leave a Reply. |

AuthorNew Zealand big data nerd, facial hair sculptor and classic car fanatic. Owner of needles.io, freelance big data consultant, ex Activision. Archives
April 2016
Categories
|
 RSS Feed
RSS Feed
