|
I update this menu list as I continue development:
I thought it would be cool to go on a journey and create something. I used to work in the computer game industry, where I would frequent studios like, getting the low down on things before most, get to play games months before any release day. One thing I found interesting is the studios spend loads of time looking at social media to help make design decisions or pin point issues. There is a plethora of information publicly available on the WWW. I'm super interested in free text and documentation classification. So, I'm going on a little bit of a mission.. create a rough platform that would help munge all this data in one place. Below is a few things that come to mind: DATASETS YOUTUBE Probably starting with the data apis, from my very thorough 2 minute read I can tell that there is some possibility to search for videos containing key words. Same as youtube, Reddit has a developer section for APIS. I could get all the latest or greatest community information from sub-reddits like r/callofduty or r/destiny. Using keywords, I could create a call from the Twitter API's for any hashtags for these games. FORUMS This is a tricker one, no API's but hey... if it's on the net it should be easy-ish. TOOLS n STUFF LANGUAGE Since leaving my last role (where I coded in python for 4.5 years), I have forced myself to only use Java for all things backend. The first couple of months sucked, but I found when I went back to Python I saw myself missing Java in pretty quick succession, so I have become a nipple high wearing tracksuit wearing Java developer.... sue me. I will probably use some Angular to do stuff and attempt to make something pretty with bootstrap. DATA STORAGE This is going to be an interesting one as I'm primarily working with text... I'm going to have a go at some graph databases, of which I seem to always get pointed to Neo4j. This will be my first time in Neo4j , so I will be a newbie and plenty of forgiveness is needed. OTHERSTUFF I will use a bunch of text based data mining techniques like sentiment analysis for measuring things like subjectivity and objectivity, which is going to be interesting due to the language gamers use to show delight or loathing is not usually typical to normal text. I will probably use jsoup as a parser for any sites that don't have any API'S. Before I start on this journey I have a few things to ask:
I plan to have a pretty crappy version up and running before the large Destiny release in September, so I can see if this even works. Hold tight! It's going to be a rough ride (mainly for me!). Go to my next post to see more
0 Comments
The more I start looking at this project, the more work if have on my plate (typical developer underestimating the work involved). I have decided for a proof of concept to stick to Destiny and Reddit as my source of community information, these will both be scalable when I'm done to extend to other games and community sites. Things I have done so far:
I didn't mention any thing about "entity information" in my previous post, but the more I learn about graph databases, I realised I need to classify the documents.. What this means is we have to label text efficiently in a way in which we can analyse it later, for example: If I looked at this reddit post, and split out the comment: "theric light allows you to upgrade old gear. It drops from nightfall, trials of osiris, and "other endgame activities." Pulls your guns up to 365 and keeps them fully upgraded" We could build a classifier that creates labels for "theric light", "nightfall" and "trials of osiris". Because I ripped what I call the Entity information (#5) I can infer this relationship pretty easily. We can also use standard text algorithms to measure sentiment, objectivity and subjectivity. Graph databases always talk about the whiteboard is your data model, it's no longer an ERD showing PK/FK relationships etc. Below is a quick example of a whiteboard based data model from the reddit post. 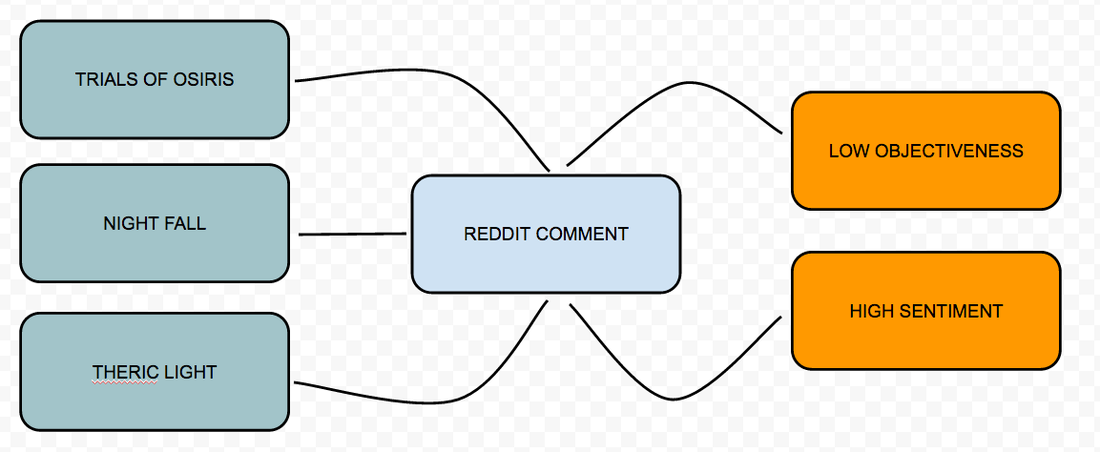 So you can tell from above, that when I'm processing my reddit comment, and putting it into a graph database I'm going to create the relationships as:
All of these relationships are going to have to be determined outside of Neo4j. As you can see I have a long way to go and by no means have I designed a finished product. I'm attempting to show the way in which I create this monster and start core development after initial analysis and design. Free-bee - Here is the repo that I ripped for the Destiny entities. Go to my next post to see how I went. INTRO Lets cut to the chase, what's the difference between vertical and horizontal big data? Vertical A platform for hundreds of thousands of customers to run data analysis on their own service. Generally this service would be a feature to an existing product, for example:
Horizontal I put this is in the more traditional data warehouse category. A team collects data from a transactional event based system, munges it into a centralized store. A team of analysts / scientists job is to provide insights back to the business to help facilitate data design decisions into their core product (yes I know there are other use cases!). Not only are businesses using data to steer the ship, but people in their everyday lives want it also. Look at the adoption of stats around fitness for example, people depend on this information to help them make better decisions and help set goals. Companies are being forced to provide insights about all subject matter back to their customers, it's becoming an expectation around most new products. THE TRICKY BIT Now I could write an article all about Hadoop and how it has transformed an industry, but I have been working on hadoop for 6+ years and you can read about that practically anywhere. What I'm genuinely interested in is the challenges in Vertical Big Data services. Let me try and draw up a crappy google image for you to help illustrate the challenge: 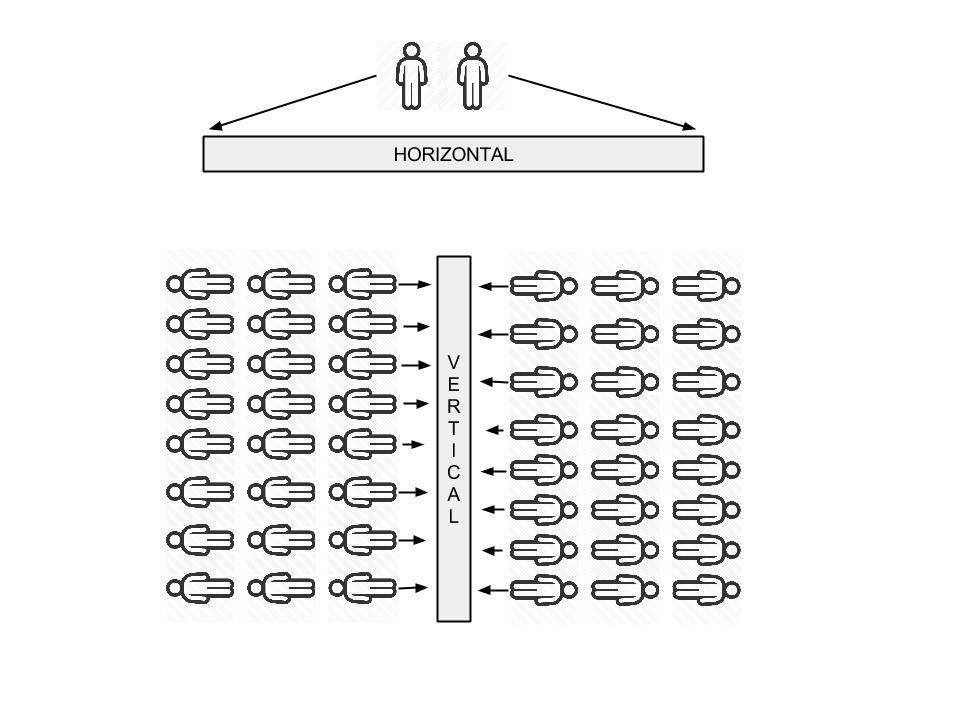 Horizontal (generalizations):
Vertical (generalizations):
HOW NOT TO DO VERTICAL You're using a product, lets say an auction site. You're a user looking for a new 2008 Honda Fit. Because you're tech savvy and like to save money, this auction site allows you to see average selling price of this particular model since it's inception in 2008 (time series). This allows you to see the models depreciation over time and will give you an idea on the selling price in 5 years when you buy a new Nissan GTR. The auctions site simply has a bit of sql like this that returns the result: SELECT avg(price), date FROM auctions WHERE make = 'honda' AND model = 'fit' AND year = '2008'; GROUP BY date; Now because the Auction house is "smart", Bill the DBA put some indexes in and it works just fine. When the product is released is all seems to go ok, after a few weeks the DB is slowly getting hammered as people are finding this new feature awesome and are using it to scan entire catalogs of makes and models to search for cars which will return the best return when they sell. What's worse is those lovely executives up on the top floor have found their magic sauce vs their competitors, "giving people reporting". They want more reports and fast, they don't care about stability as that's Bill's job, in Canadian.. they're saying "Git er done". Bill has three options:
Don't mix and match OLTP and OLAP to make some bastardized child "OLTPAP. Generally only use your transactional core product database for singular CRUD activities. If you're designing something that has any level of aggregation, that means your transactional data is working much harder. Modular separated services always win, if you design a new stack and it goes down due to load, it doesn't bring down the core product, customers are less angry, sure they don't know the history of Honda Fits, but they can still buy one. A high level of the wrong stack could look like this: 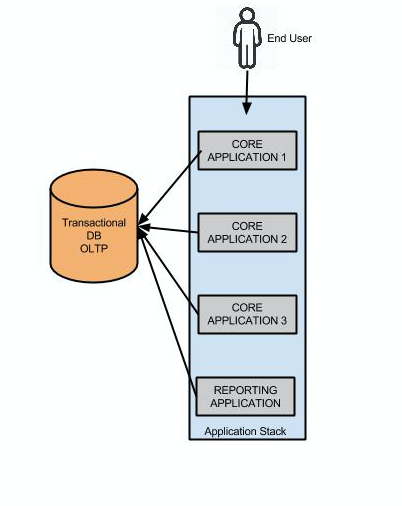 Separating out the customer reporting could look like this: 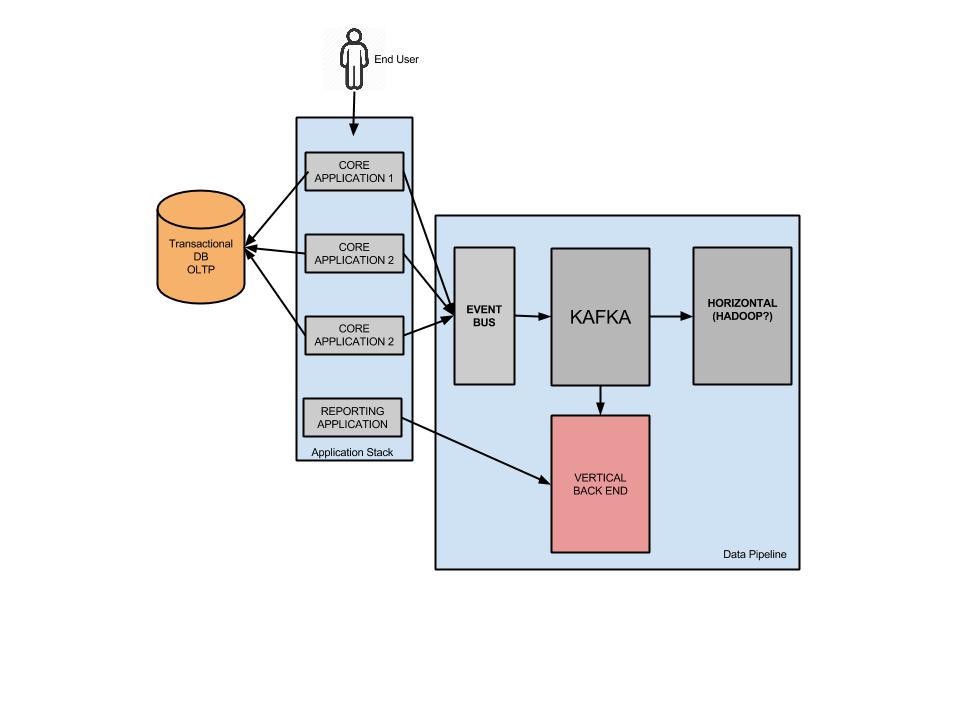 As illustrated above, we could utilize technologies like Kafka and Event buses (API ingestion) etc which can work in near to real time. The big questions is, what can go into that pink box to serve 100's of aggregated queries per second? There are a few options which I will run through. THE OLD TRIED AND TESTED You have been working with MYSQL for 10 years, you probably wrote your own sharding application, you flip master / slave roles and servers in your sleep. The developers can use their existing ORM to develop out of. The only issue is you're basically replicating your transactional db and it's not very cost efficient when you do the math. I won't go further into this one. DRUID.IO This lil guy popped into the scene a few years ago and is used quite widely internally at companies like NetFlix and EBay. In their words Druid is: Query timeseries data as it is being ingested for both immediate and historical insights. Aggregate, drill-down, and slice-n-dice N-dimensional data with consistent, fast response times. The way it works illustrated: 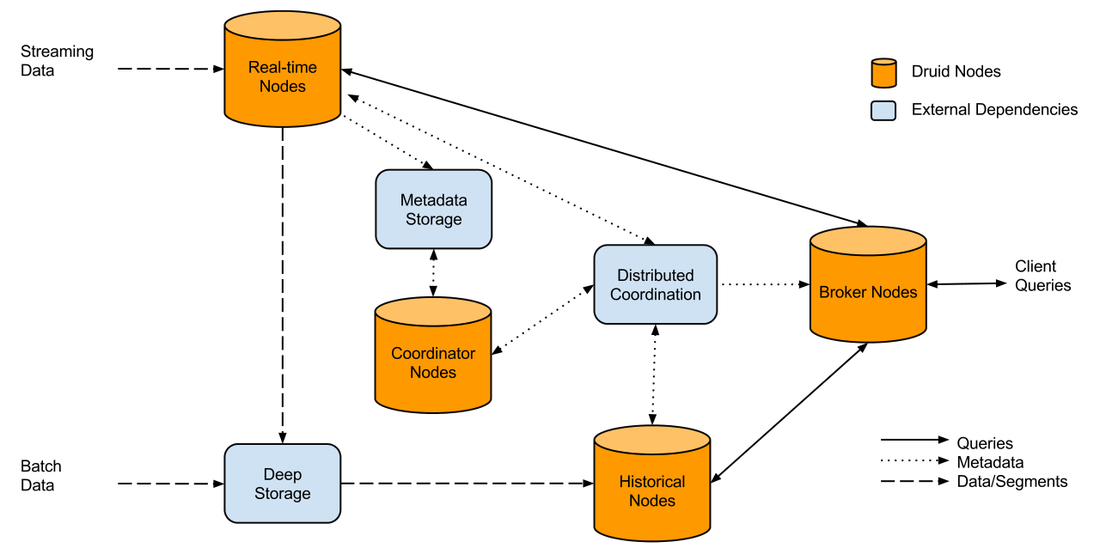 It can look a little daunting, and there is a lot moving parts (not as simple as a master/slave topology), but it is powerful in it's own right.
How does it work: It kind of cheats behind the scenes, once you send through an event it will roll it up based on the schema you provide the event , so three raw events might look like: customer_id, store_id, total_purchase, date 123 , 1 , $12, 2015/01/01 123 , 1 , $15, 2015/01/01 123 , 2 , $5, 2015/01/01 It would roll up it as so customer_id, store_id, total_purchase, date 123 , 1 ,$27 2015/01/01 123 , 2 ,$5 2015/01/01 Your dimensions in the druid schema would be: store_id and customer_id, metric would be total_purchase, granularity_spec set on "day" If your dimensions don't change very often, it has the possibility to be really good at rolling up to a handful of segments types. Pros
One thing I'm unsure of (didn't want to put it as a pro or a con) was could Druid handle 100's of queries a second? There might need to be a cache in front of druid which periodically pulls in fresh data, adding more complexity. NOSQL Take your pick! I'm going to be platform agnostic on this one (eg: cassandra, riak, mongo). But actually storing data inside an object per customer could be pliable especially if you have a low number of events per dimension(s). Storing the data but getting your application stack to do the aggregation at this level could be worth it. Now, this only works if the aggregations you want to provide are silo'd to a particular customer. If we use the example of the Auctions over time (as above), NOSQL could provide a little bit of a mess (aggregation over thousands of objects). But again there are several work around to this, you could run the aggregation in Hadoop which populates new service wide data views). SPARK STREAMING or STORM (my preferred option). Storm is the more mature platform, but Spark is being adopted at an alarming rate! Both require you to have your aggregations in memory (don't believe the lies). To facilitate less memory usage, writing out completed aggregation segments to a NOSQL solution like Cassandra can save you in the long run in terms of memory costs. Spark and Storm can run on Hadoop, so Hadoop can leverage the data as well for Horizontal type analysis. CONCLUSION Don't use your OLTP for aggregations, not even once. Do a bit of a brain storm on what types of reporting you plan to deliver to your customers now and in 2 years time, this kind of planning will save you all kinds of technical debt in the future. Is your reporting silo'd to one customers data (eg: financial)? Or are you going to share events from your entire customer base into the reports (eg: auction house). This will dictate the direction you need to go with in terms of picking the right tools. TLDR: DO THIS SURVEY IF YOU ARE/HAVE BEEN IN A STARTUP
I have had the awesome opportunity to be a part of two start ups so far!In my experience the DNA of start-up employees are different than your commercially oriented ones (open for debate). I feel it's easier for us to feel like we are individually making an actual impact without blending into commercial life. I have been a manager for 7 years and I have seen many emotional roller coasters people have gone through before they leave . When ever I ask the question "why are you leaving?" 80% of the time they find it hard to put a finger on exactly what has changed or made them unhappy. Because I'm a data guy and one day I would like to start "my own thing" I would like to take any opportunity to learn why people are leaving and better understand the reason behind it. I chucked together a really rough survey which should help us better understand these reasons. Of course, if I get enough responses I will be throwing together all kinds of graphs for anyone interested. Hey you! Thinking about setting up Kafka? Gonna spend lots of money on super high spec machines? You know.. because processing millions of messages per second must need a billion cores, 124 wheel barrows of ram and a specialized SAN with 400 high speed SSD's. Well if you work in one of those horrible companies where your CTO's idea of product evaluation is forming partnerships with shitty vendors just to get a free cruise with 5,241 other wheel chair bound executives you might be screwed, BUT... if not then read on. NetFlix touts they are processing around 1.5 million events per second on peak.(I bet 90% of them are error logs.. jokes... well not really.. but I love Netflix). In my mind I was thinking.. that must require a fairly size-able cluster.. but like any engineer I wanted to see what kind and number of machines I would require to process "Netflix Scale" on Kafka. So, my test scenarios are below: Generic Across All Tests Zookeeper Node - r3.xlarge (30GB Memory, 4x vCPU, 1x80SSD) Producer - 3x m3.xlarge (7.5GB Memory, 2x vCPU, 2x32SSD) Zookeeper throughout the tests didn't flinch passed 10% on any benchmarks (but one node certainly isn't recommended in a production environment). Test 1 - General Purpose Nodes Brokers - 3x m3.xlarge (15GB Memory, 4x vCPU, 2x40SSD) Test 2 - Memory Optimized Nodes Brokers - 3x r3.4xlarge(122GB Memory, 16x vCPU, 1x320SSD) Test 3 - Well crap, I was stunned by the other two, I'm going to try something really bad. Brokers 3x m3.medium (3.75GB Memory, 1x vCPU, 1TB of magnetic EBS ..that's a max of IOPS of ~200!) Producers: We used the "org.apache.kafka.clients.tools.ProducerPerformance" class provided with Kafka to perform the tests. The producers each push 50,000,000 events with a payload of 100 BYTES each (thinking singular key-value events that you might push to something like Graphite), I also had async enabled and was batching events. Results: Test 1 (m3.xlarge) 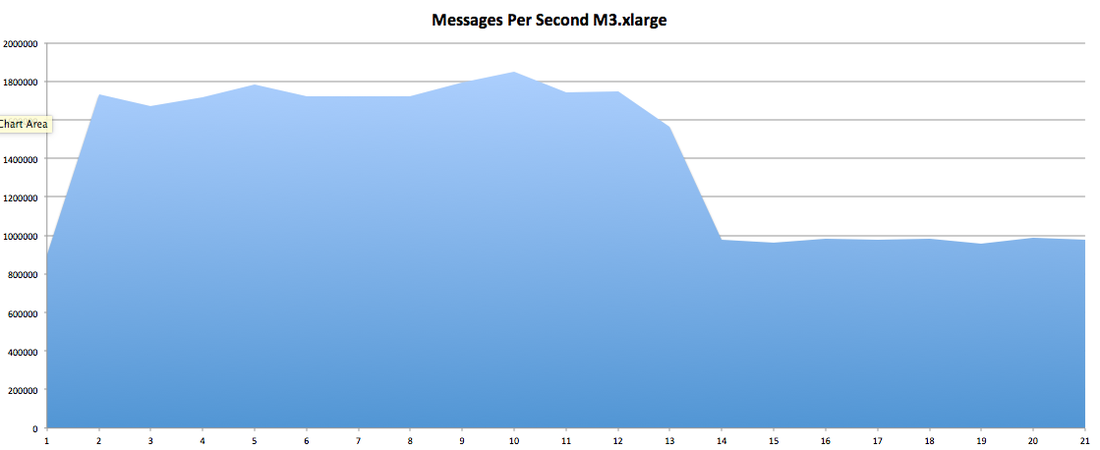 We hit a peak of 1.83 million records per second. You will see a sharp drop which is hard to explain as all of the producer nodes we used were exactly the same. One of the producers had the ability to process data 80% faster when it was the same spec as everything else is something I would put down to "cloud ghosts" if I had time I would have dug into more. Below you can see the graph by producer node: 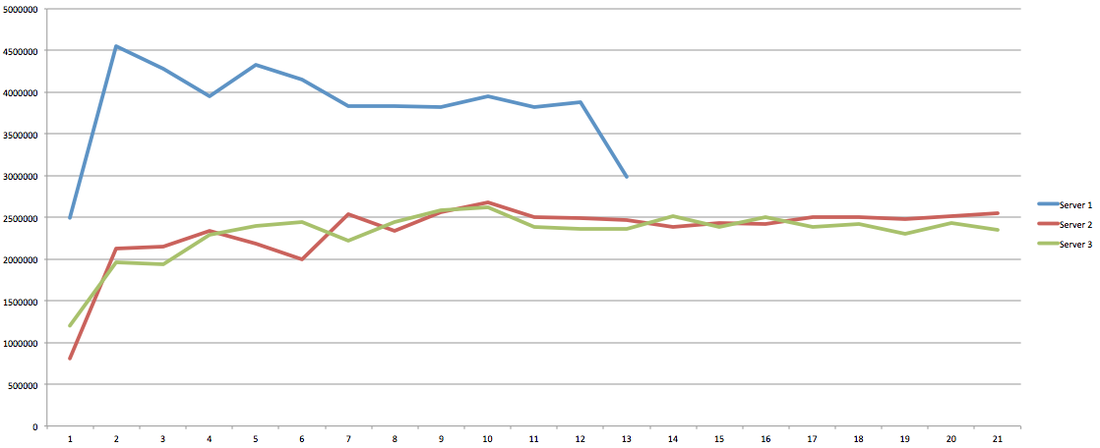 Details below pertaining to bytes in and out of the interfaces 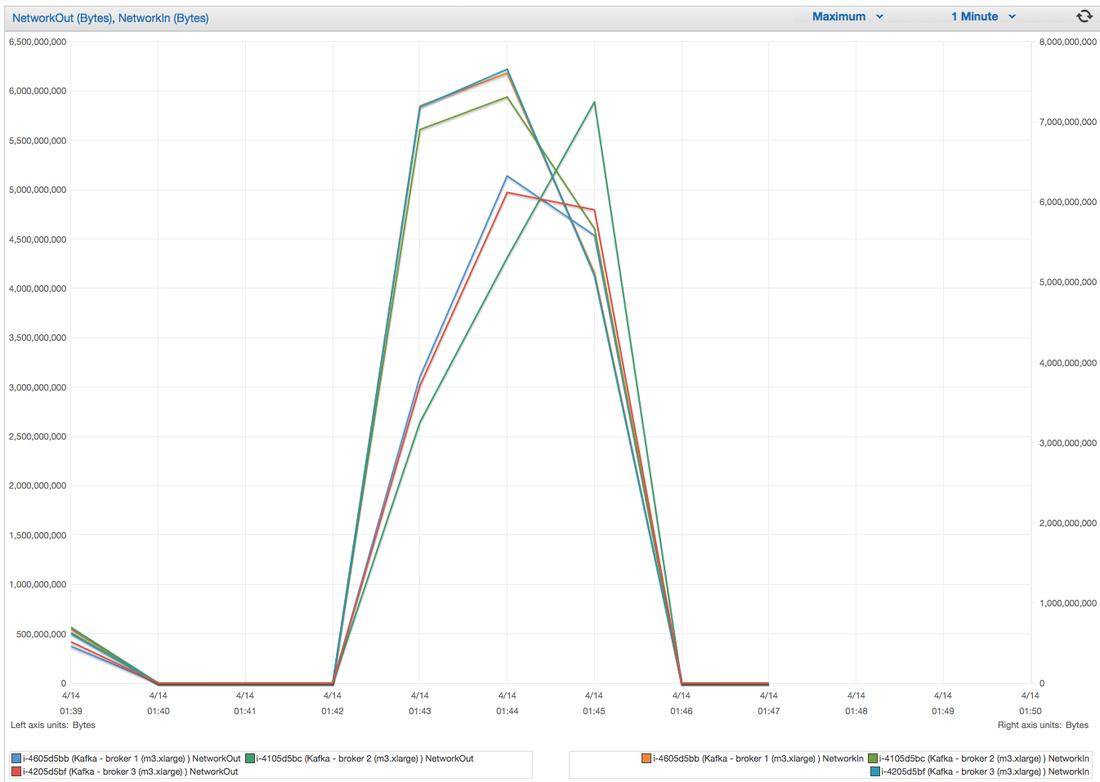 The last peak is ONLY relevant to the test (apologies!). We reached a peak just shy of 55% CPU utilization. 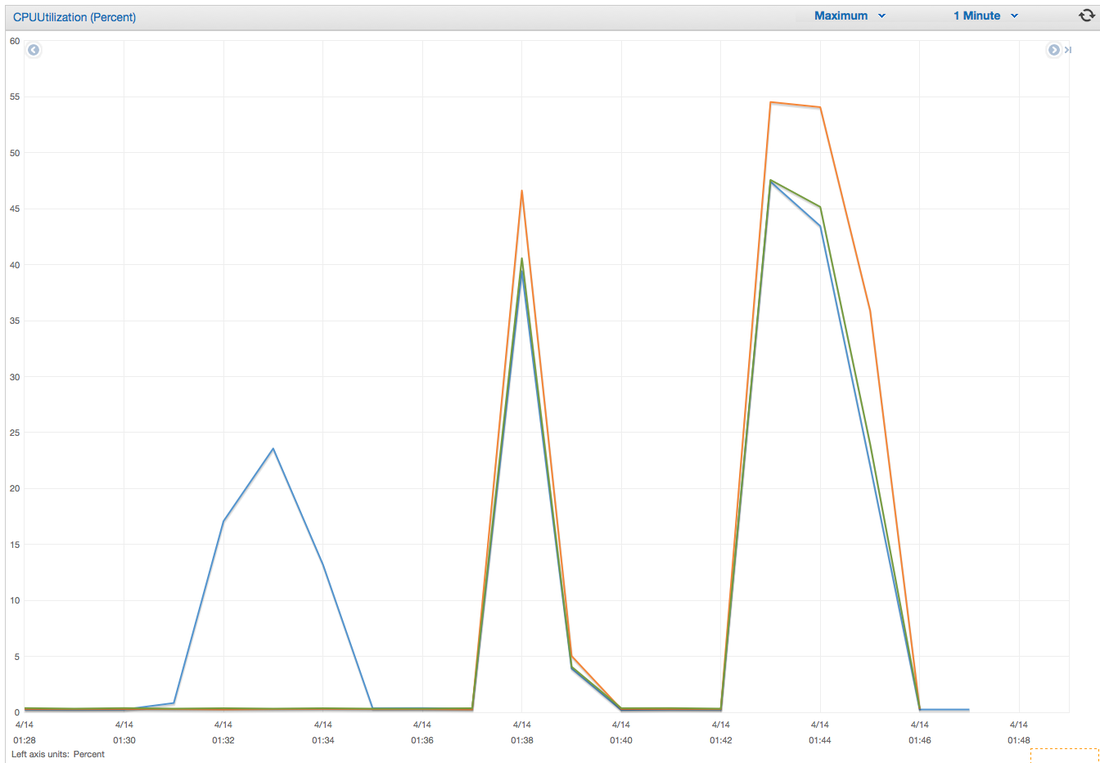 Results: Test 2 (R3.4 xlarge) 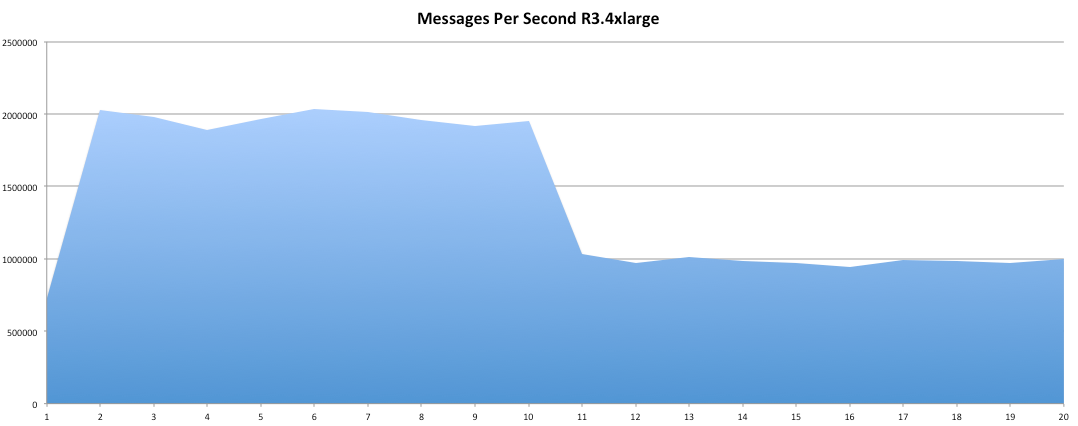 We peaked with just over 2 millions messages a second, again the same pattern shows that one producer is out performing the others quite a bit. 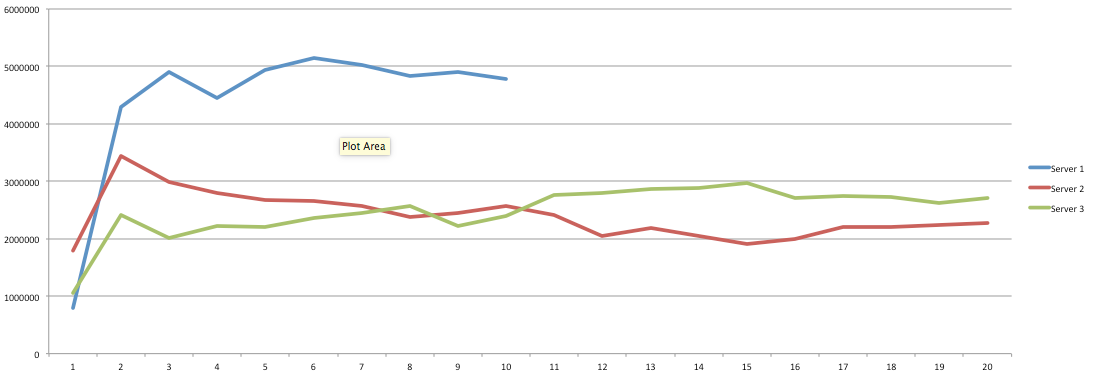 As the same in the last test, you can see producer server 1 leaping ahead and completing its messages much faster than the others. 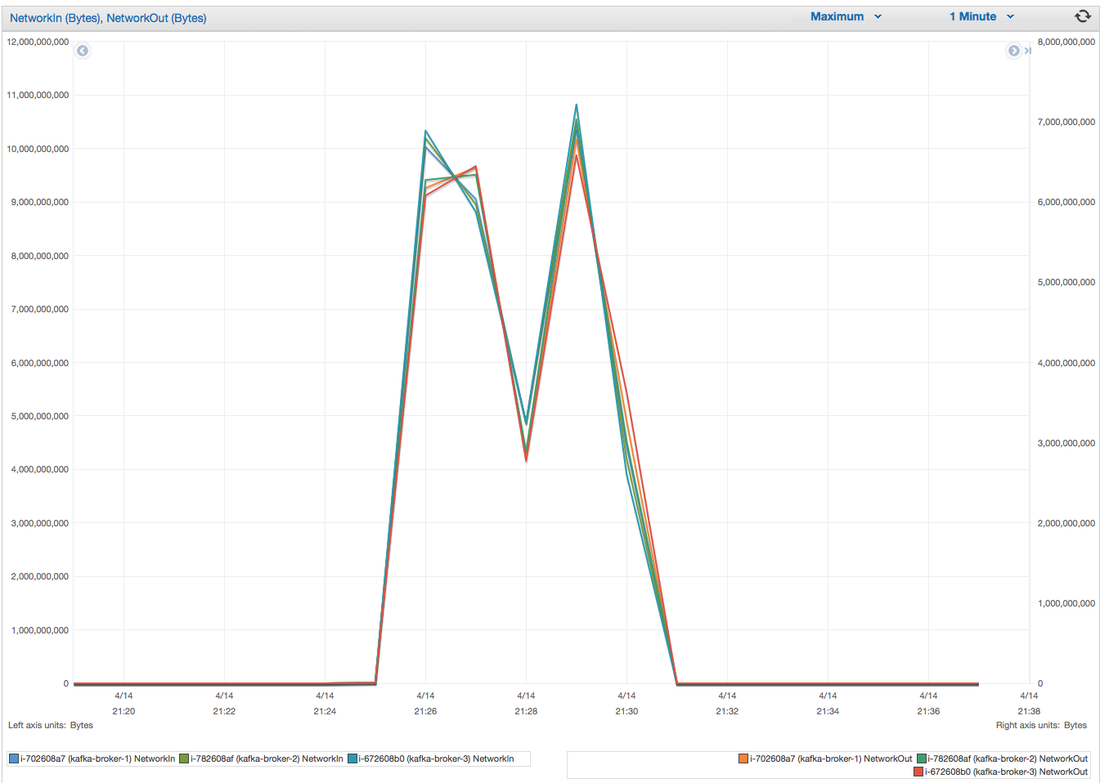 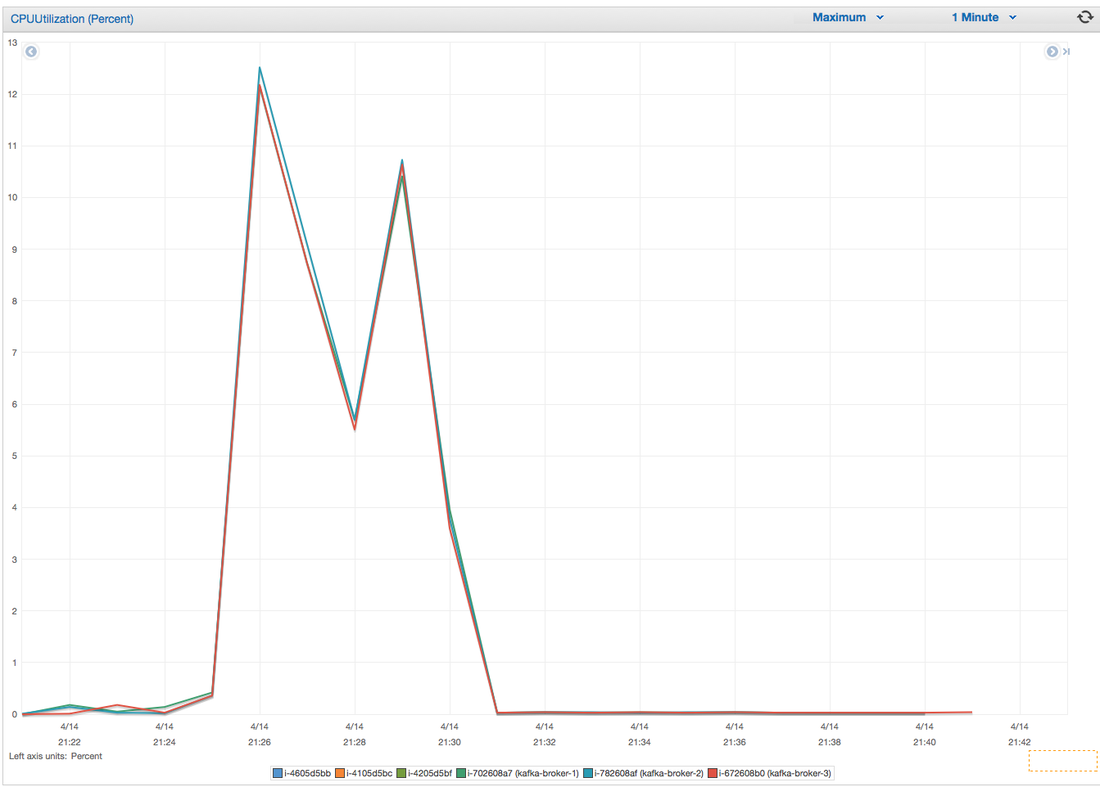 When you have 4x as many vCPU's, you have more lying around gathering dust. Results: Test 3 (m3.medium with EBS crappy disks) 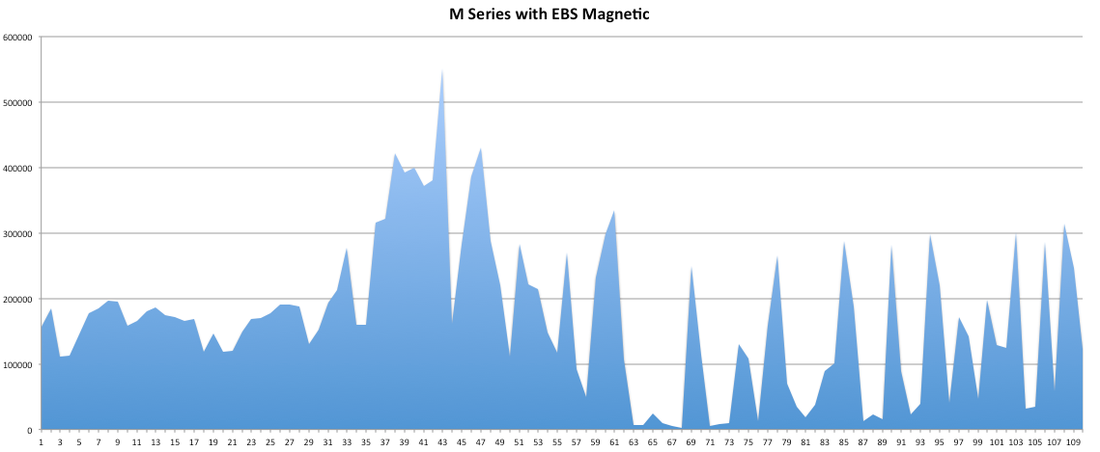 Woah there Nelly! Spiking up to ~550,000 messages per second and dropping to a low of ~2,400 per second, I guess when Amazon says "used for infrequent data access" you should maybe think twice about Kafka with magnetic EBS. 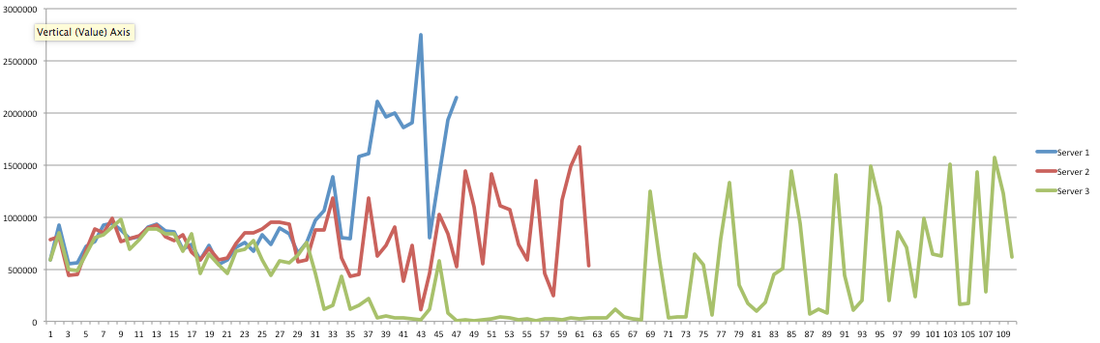 You can see the 3rd Producer node had a tough time of it, taking almost 2x longer to process 50mill events. 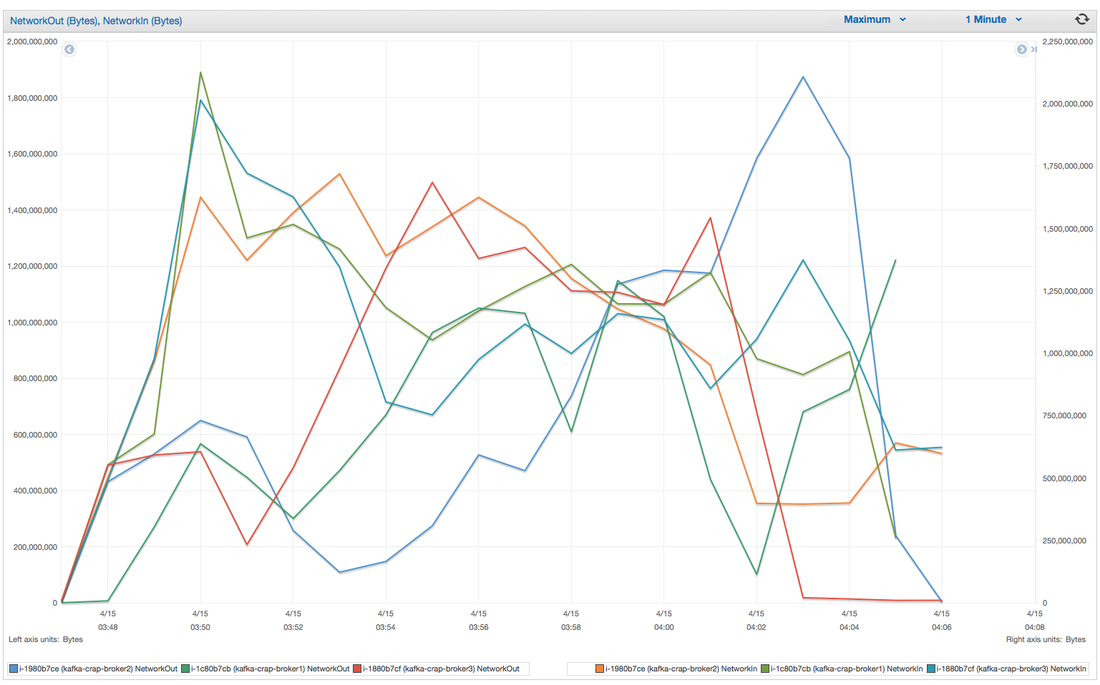 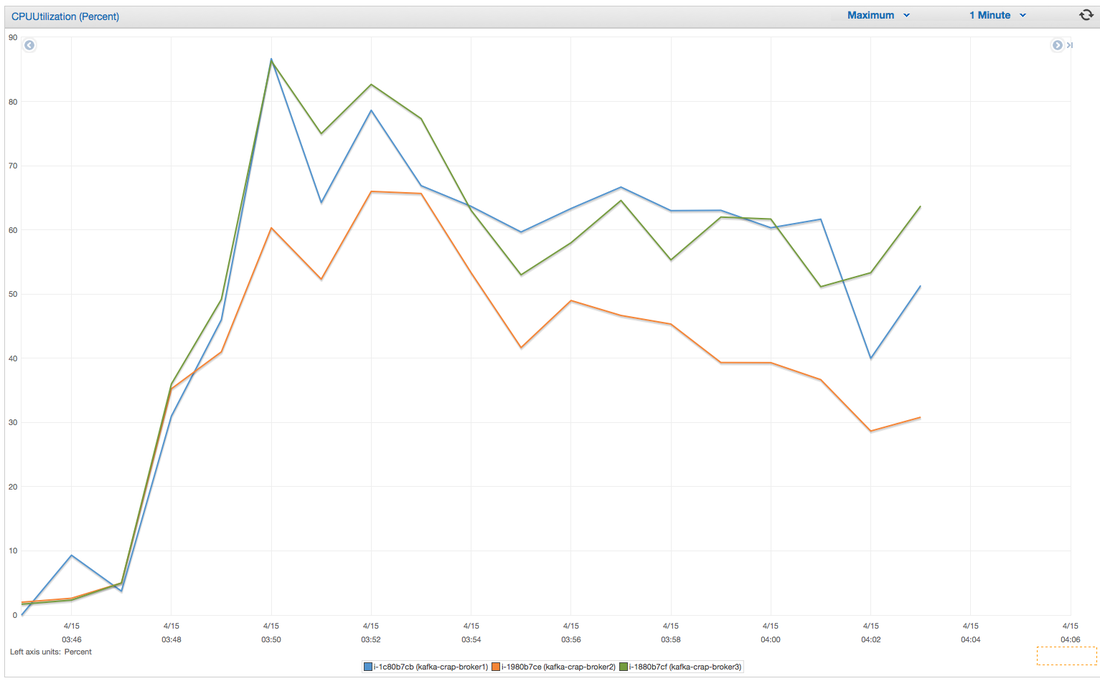 Network is all over the show, CPU is spiking up around 90%.
CONCLUSION Are you Netflix or Linkedin? Probably not.. but we did prove that we could process over 2 million messages a second? YES! and with the R based nodes we had room to grow! My aim was to prove that you can deploy something like Kafka, process shit tonnes of data along with it not breaking the bank! Although the R series had room to grow, I believe the m.series (not with EBS magnetic) is up to the challenge. I would have liked to have spent some time in the EBS SSD area with ranging payload sizes but these sets of tests have taken some time in their own right. The extra costs associated with your retention & replication policy coupled with firing around 1.5 million messages per second with our small payload of 100 bytes is around 150MB a second, when you do the math it gets pretty costly (if you have that many events I'm assuming your company is rather large and has deep pockets). We didn't fire up any consumers while the producers were running but I decided that since Jay saw very little difference between running with consumers and producers I left it out due to time. Update - Netflix are now saying 8,000,000 m/s during peak! Even with such an increase this is still very do-able on very basic kit in Ec2.
Continuing on from my post about installing kafka on Ec2, Kafka doesn't have (yet) any really good UI's for monitoring or maintaining your cluster, so I decided to have a hunt around for some open source goodies. I checked out a couple and landed on evaluating Yahoo's Kafka Manager, I chose this over kafka-web-console only because it was made by Yahoo and I'm making the assumption that it's well maintained (I could pay for this later on) and considering the last commit to web console was 9 months ago I think I made the right choice.
Update - As I started playing around with Kafka Manager it became apparent to me that this tool was only intended to be used as a UI for administration tasks, not for monitoring health (such as lag) of existing production topics. So soon enough I will also be looking at web-console. Previously we had built our own monitoring solution with bastardized angular and bootstrap, but it was painfully slow and took many developer hours to maintain it (the slowness could be down to the JMX reporters and thousands of topics). Step 1 - Download and extract the package If you followed my previous post, I set up a node for zookeeper and I'm going to install Kafka manager on here also. So, you will need to first SSH onto the Zookeeper Node and download the package from GitHub, unzip and then rename the dir. _ wget https://github.com/yahoo/kafka-manager/archive/master.zip
Step 2 - Install sbt
If you're like me and you don't have scala installed you will need to grab it (it doesn't seem to be as easy as "apt-get install sbt"). Below are the commands to run to install scala manually. wget -q apt.typesafe.com/repo-deb-build-0002.deb
Step 3 - Build your kafka-manager scripts
Cd into your new kafka-manager directory then run the build command. cd kafka-manager 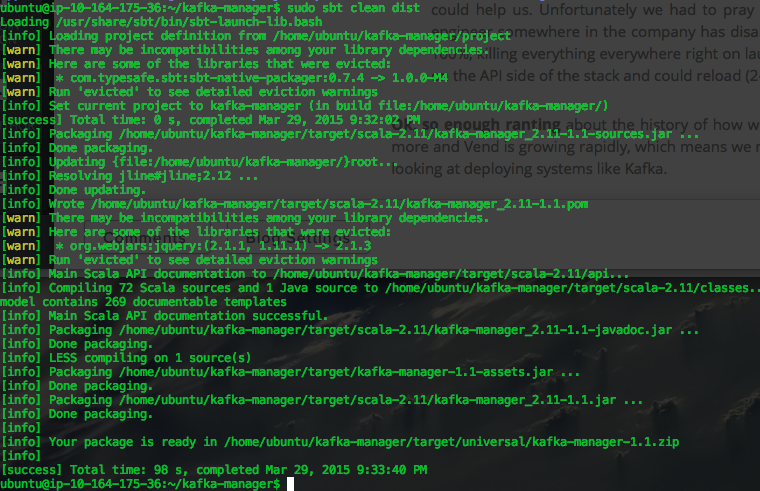
As you can see there are a few warnings around existing library conflicts, but all is good. It has generated a zip file, see the line "your package is ready in ...".
Step 4 - Copy that Zip file to a suitable location and unzip sudo mv target/universal/kafka-manager-1.1.zip ~/
Step 5 - Some weirdness and a hacky work around..
Yes you would expect a conf file to point the manager to a Zookeeper host(s) of which there is a such a file, but for me at least it didn't work, I tried the dns, the ip and since I'm running this app on the same host as the Zookeeper node I also tried localhost...none of them worked. In case you have better luck than me below are the entries that need to be made: The conf file is located at: "conf/application.conf" and alter the zkhosts entry Below is the command I ran to over-ride the conf and it worked just fine. bin/kafka-manager -Dkafka-manager.zkhosts="localhost:2181"
Once that's started, you should be able to open it up in a browser using the standard port 9000.
Step 6: Initial Setup and adding a cluster
Go to Cluster -> Setup a new cluster. 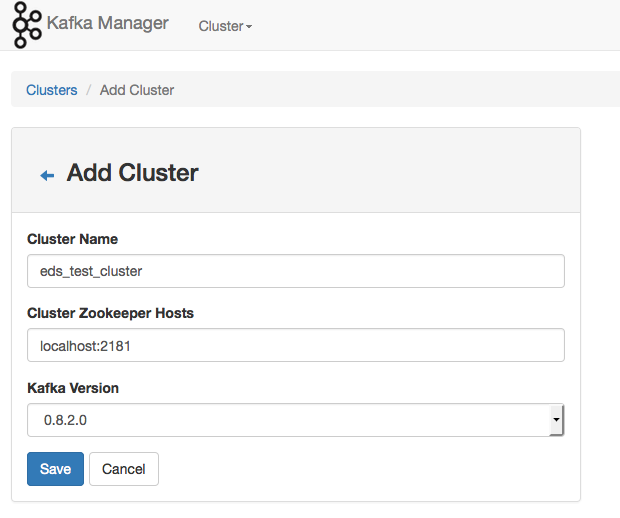
For this evaluation I'm running my Kafka Manager from my zookeeper host, I only have one host for my tests but if you have multiple hosts, just add them in as "host1:2181,host2:2181" etc. I'm using Kafka 0.8.2.x. Hit the save button and some magic should happen.
You can now see it's picked up my cluster and the existing 2 topics I created. If you have an existing topic in your cluster, you can click on it and explore from there. 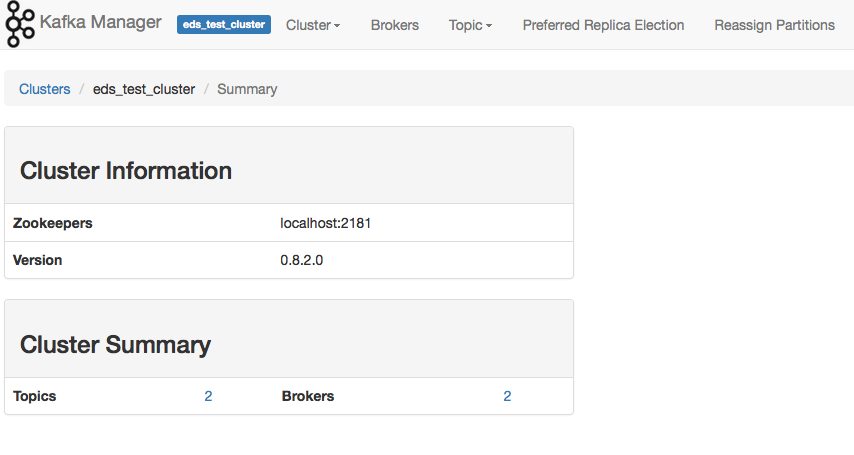
Creating A Topic through Kafka Manager.
In the top menu, click on topic and then create. You are presented with a bunch of parameters that you might be accustomed to from using the stand CLI. Once done there click on topic view. 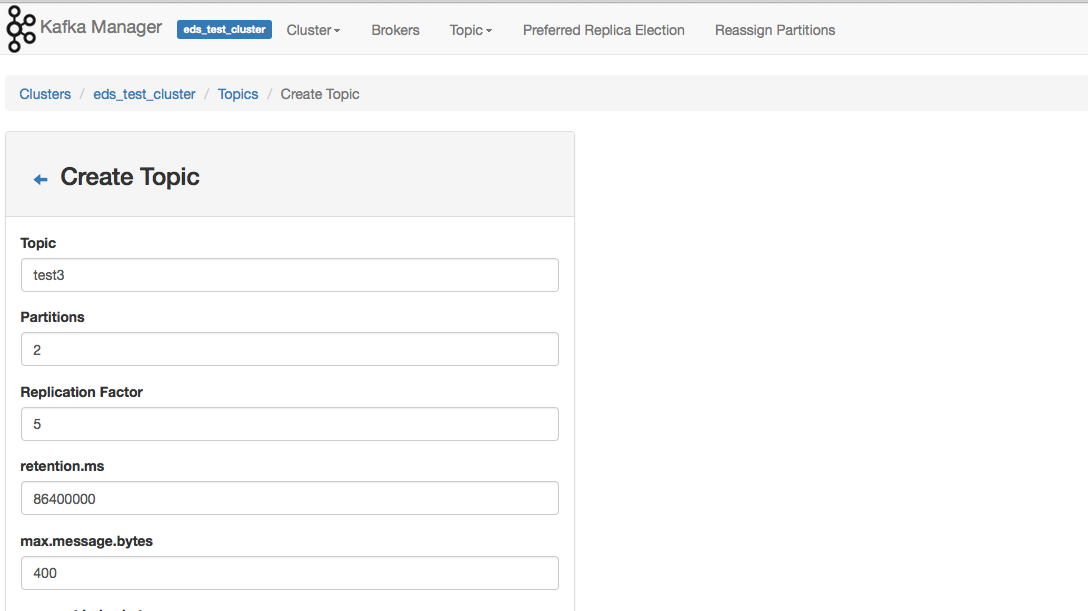
Topic View
We created our topic, now we can see it in all it's glory! If you're old hat to Kafka... you'll be pleased to know that the topic "delete" function.. works!. 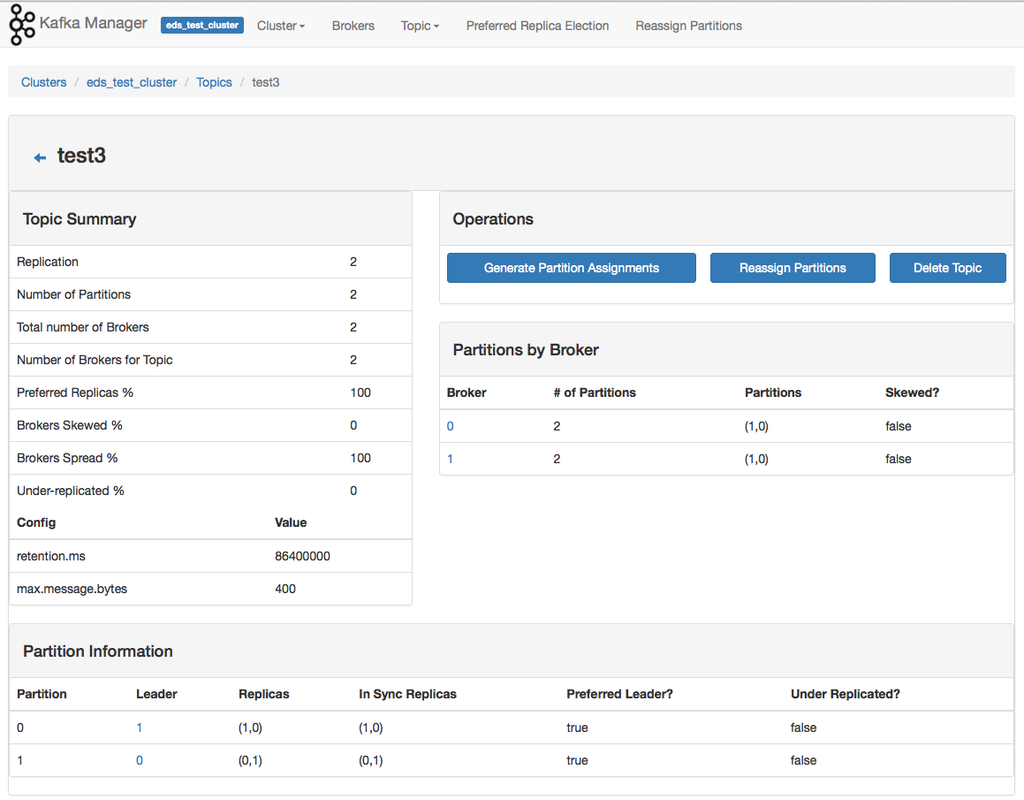
Brokers
Clicking on the broker menu item, provides you with a summary of your brokers. 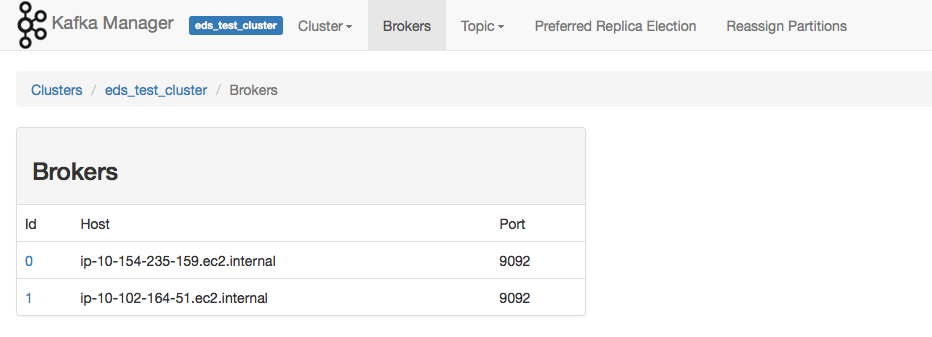
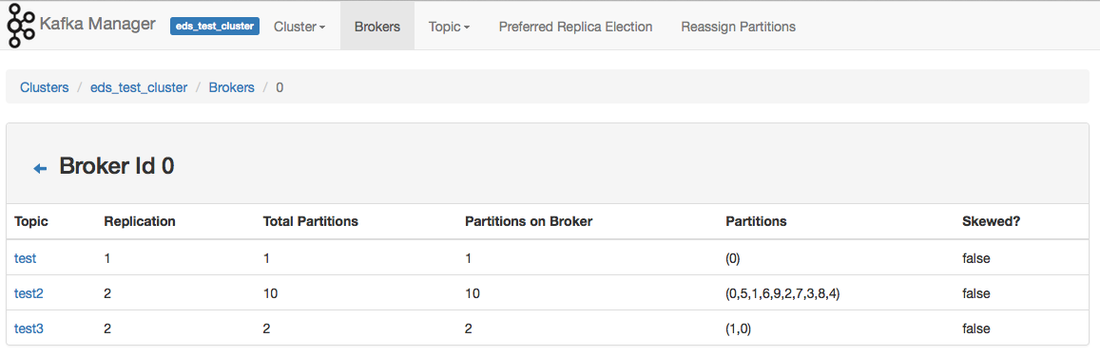
Clicking on one of the Brokers will provide you with a summary of the topics and partitions.
Re-assigning Partitions
This bit was a little buggy for me, I created a test4 topic and deleted it (out of this example) and it's still showing up as an option to reassign. When I selected test4 it then presented an error that it didn't exist. 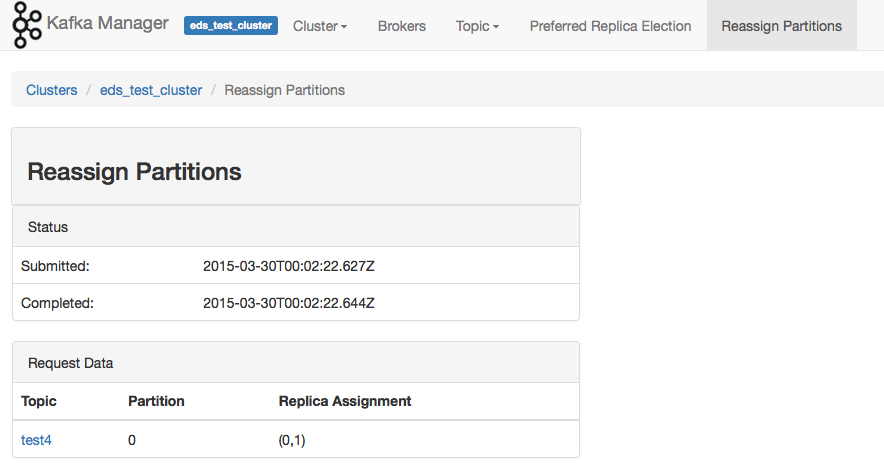
Conclusion
This is a very very simple application, for some reason I assumed because it was made by Yahoo it would provide more features. When you should use it: I think it would be useful on an enterprise level where system engineers don't have to always go through the CLI to complete their work, where engineers complete 5,000 tasks a day and this is just one of them. It enables you to digest the information pretty quickly. Cons I guess I expected more? Maybe I'm being greedy? I would love to see some metrics of cluster health around topic consumer lag etc. I'm assuming that since Yahoo is large scale they use standardized health metrics systems across their applications and they have something already feeding into that. Who knows? Kafka is pretty young in the terms of things and we could see this project grow. (Also it screams bootstrap).. confirmed src it's bootstrapped. Keep posted as I dive into web-console. 
Step 2: SSH into your new Zookeeper node In case you're new to Amazon like me, it's best to create some keys, provide them to EC2 and when you're provisioning your new node select your keys!
Well, here we are again Kafka my old friend..
I'm new to EC2 but my experience so far has been good. I wanted to throw this tutorial together not only for others, but for myself as a "remember how you did this guide". Step 1: Pick some random instance types I'm going to go ahead and pick 1 smaller node for Zookeeper and 2 nodes for Kafka. I used Ubuntu Server 14.04 LTS, I deployed the following types of nodes:
Tip: Ensure you have a security group enabled and selected when you create your servers, once they are initiated you cannot switch groups (I found this out the hard way), also add in the firewall rules so that your servers can talk with one another. Look at me, I have a zookeeper node!
You should start seeing a bunch of stuff on your screen, look for any warnings or errors.
Step 4 - Install some Java love
Step 5 - Fire up Zookeeper
wget http://psg.mtu.edu/pub/apache/kafka/0.8.2.1/kafka_2.9.1-0.8.2.1.tgz
Step 3 - Download the latest package & unzip etc.
Remember to download the latest Kafka, you can check for versions here. We are going to be lazy and setup a single instance Zookeeper cluster. (remember to download the bin and not the src). cd kafka_2.9.1-0.8.2.1/ sudo apt-get install default-jre ssh -i ~/.ssh/your_ssh_key ubuntu@ec2-##-##-##-##.compute-1.amazonaws.com 
Step 6 - Fire up a couple of data nodes in EC2
Open up another terminal window and check that the zookeeper process is running: "ps aux | grep zoo"

Step 7 - Do the same on these nodes!
SSH into the data nodes and complete steps #3 and #4 again.
Step 8 - Change the configs for the data nodes
We need to update the data node configs to be able to talk with the Zookeeper node. In the terminal go to (use Vim or what ever text editor you like to fight over which is better).
Alter the following lines in both the data nodes:
nano config/server.properties broker.id=0
The broker.id is a unique integer, so if both of our data nodes are set to 0 we are going to have a bad time, change one of them to 1.
With zookeeper.connect you should change this from localhost to the ip address of the zookeeper node
Step 9 - Start up the data node servers!
bin/kafka-server-start.sh config/server.properties 
Same as the zookeeper node, you should start seeing messages spilling out to screen, ensure there aren't any warnings or errors in these logs.
Step 10 - Time to test this sucker!
Open up a new terminal window for each of your data nodes. We want to create your first topic, in the code below where it states "zooKeeperHostIP" replace that with the IP address of your zookeeper node. Run this command on either of your new terminal windows. bin/kafka-topics.sh --zookeeper zooKeeperHostIP:2181 --create --topic test --partitions 1 --replication-factor 1
Check to see if the topic has been created
bin/kafka-topics.sh --zookeeper zooKeeperHostIP:2181 --list
On one of the terminal windows, start up the consumer
bin/kafka-console-consumer.sh --zookeeper zooKeeperHostIP:2181 --topic test --from-beginning
On the other terminal window, add a producer:
bin/kafka-console-producer.sh --broker-list brokerOneIP:9092,broker2IP:9092 --topic test
Now.. on the terminal that you created the producer in, type "hello how are you!" Then watch the message appear on the consumer terminal window.
Producer: 
Consumer:

You might see a warning on the producer, "WARN Property topic is not valid" don't worry about that it seems like it's a bug.
Well done! We built our first multi-node Kafka cluster in Amazon EC2! I plan to expand on this in the coming weeks on monitoring and performance testing different instance types in Amazon. |

AuthorNew Zealand big data nerd, facial hair sculptor and classic car fanatic. Owner of needles.io, freelance big data consultant, ex Activision. Archives
April 2016
Categories
|
 RSS Feed
RSS Feed
